This guide is for non-technical people who want to understand how attribute release enables secure and privacy-preserving access to online library resources using federated identity management. If you first want to read up on what federated identity management is, you can find a basic introduction here.
What are attributes?
Attributes contain information about an end user that are passed to a publisher or service provider after authentication. Think of a name, email address etc.
An end user working or studying in the Research & Education (R&E) sector often has a user account with their institution. Their institution is the ‘identity provider’ of the user, commonly abbreviated as IdP. During an online authentication workflow, the IdP can often provide additional attributes about the user1 to the organization initiating the process (also known as the Service Provider or SP).
Why are attributes important?
Attributes can be used to transfer information about the end user from the IdP to the service a user wants to access. For example, attributes are commonly used for:
| Use | Example |
|---|---|
| Access control | e.g., only allow users who are full-time staff |
| Cost control | e.g., only allow users with a certain role, or from a certain department |
| Risk control | e.g., avoid the need for (i) users to separately register a username/ password and (ii) 3rd parties to store credentials |
| Convenience | e.g., save search results for subsequent access. And avoid the user having to provide duplicative information to the SP that their IdP already holds |
Attributes and attribute release can be very helpful in ‘doing business’ and enabling users to do their work. To protect user privacy and comply with data protection legislation, it is important to limit the release of personal data.
Types and examples of attributes
These attributes can be classified according to the amount of information they reveal to the SP about the user:
Anonymous identifier:
- Some services want to receive an identifier, for example because they technically need one. The IdP can generate identifiers2 that are unique for every visit and SP
- Real identity unknown (anonymous)
- Does not allow for personalization
Pseudonymous identifier
- IdP-generated identifier3 unique per person/SP-combination
- Real identity unknown by the SP (pseudonymous)
- Personalization possible
Organizational
- Home organization, Entitlements, Role, Department, Location, etc.4
Personal
- Name, email address
How does attribute release work?
In general, the flow goes as follows: a user lands on a web page of a service (an SP), often via a search engine like Google, and clicks a login button that brings them to their IdP, while the SP specifies what attributes it would like to receive. The user signs in at their IdP. After successful authentication, the IdP redirects the user back to the service, while providing zero or more attributes. Graphically:
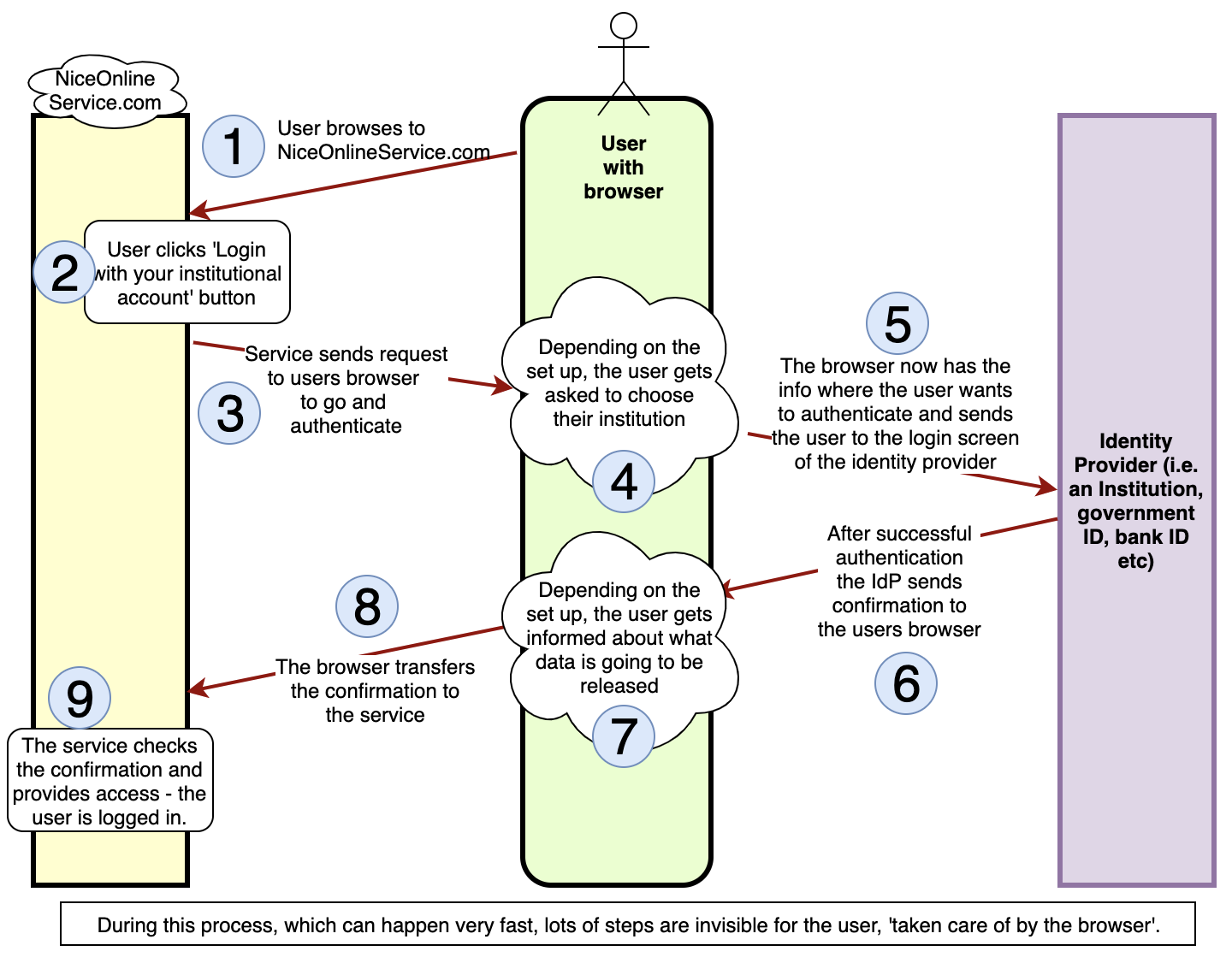
The IdP is always in control of what attributes are released to an individual SP, and has a responsibility to limit attribute release and protect the users privacy. Depending on the national legislation, IdP’s should check to see whether they need a contract between the IdP and SP to release personal information that defines, amongst other things, what other attributes are necessary and how the privacy of the user is protected.
RA21 and recommendations
RA21 has adopted the GÉANT Data Protection Code of Conduct (DPCoCo), an R&E-led initiative that defines behavioural rules for SPs that want to receive user attributes from IdPs. The DPCoCo sets the stage for compliance with the principles behind the EU General Data Protection Regulation (GDPR).
RA21 recommends:
-
For SP’s:
- Only request the least intrusive set of attributes; what you need, not what you want.
- If the service thinks it has good reasons to request more information from the user, the service should provide a profile page in the service, so the user can, on an individual basis, enter more information (like a name, an email address etc).
- Do not retain any extra attributes that you receive.
- Do not use attributes for non-access purposes without prior consent or proper legal basis.
- Delete or anonymize all attributes when no longer needed for service access.
-
For IdP’s:
- Limit attribute exchange during authentication.
- People from IT and libraries to start working together, to discuss attribute release, minimizing attribute release, and informing users about what data is exchanged, why and on what grounds
-
For both:
- Only share anonymous or, if necessary, pseudonymous attributes.
- Make sure there is a proper lawful basis for exchanging attributes.
Here are some example scenarios showing how attribute release can enable different levels of personalization for the user:
| Scenario | Attributes |
|---|---|
| Users access a website or resource that is access controlled by provides full-text articles with no options for personalization | Anonymous attributes |
| Users access a website that provides personalised get content recommendations in its UI based on prior visits/history | Pseudonymous ID |
| Faculty have the ability to purchase ebooks using library funds | Pseudonymous ID, User role |
| Clinicians receive email confirmation of Continuing Education credits received | Pseudonymous ID, User email address (with user consent) |
Related resources
See also: VIDEO: How Federated Authentication Works provides a conceptual understanding of how this technology enables more seamless and privacy-preserving access, including definitions of key terms, such as Service Provider, Identity Provider, and Identity Federation.
FOOTNOTES:
-
Technically, an organization can be (one of many) attribute providers for a user, without also being their identity provider. Typically, an R&E institution acts as both identity provider as well as the main (or only) attribute provider. ↩︎
-
As an example: in SAML the ‘NameID’ attribute can be used to communicate a transient id. The Shibboleth wiki has a nice overview of identifiers. ↩︎
-
As an example: in SAML the ‘Pairwise Subject Identifier’ is the current state of the art identifier (while in older configurations ‘eduPersonTargetedID’ and SAML 2.0 ‘persistent NameID’ is still being used). ↩︎
-
Not all federations release the same set of attributes. But there is a core set which most can supply. ↩︎