General
Important update on 3rd-party cookies and SeamlessAccess
The summary: good news!
As mentioned in our last blog post, Google’s recent announcement about their continued support for third-party cookies left us with some unanswered questions about what that exactly means for SeamlessAccess. In particular, what was not clear from the brief announcement text is what impact this change of direction will have on SeamlessAccess’ ability to remember the user’s choice of institute across participating websites, an important part of the usability improvements that SeamlessAccess offers.
Following more detailed conversations with the team at Google and detailed tests by the SeamlessAccess team and others, we are now able to confirm positive news: SeamlessAccess will continue to be able to offer global persistence (i.e., the ability to remember the user’s choice of institute across participating websites) for Chrome and Chromium-based browsers like Microsoft Edge. This applies to all SeamlessAccess integration patterns - Limited, Standard, and Advanced - with no or limited effort for integrators.
Caveat: Although this appears to be the long-term direction that Google is now settling in, we cannot exclude the possibility that this might again change in the future. Also, behavior in other browsers will be different - more on that in the below.
The back story
Over the last several years, the team at SeamlessAccess has closely followed developments at browser vendors related to third-party cookies and other mechanisms that can be used to track users on the web (see e.g. this blog post). This journey started several years ago, when new legislation was introduced that led browser vendors to review their safeguards for user privacy.
User privacy is a key value for SeamlessAccess, and the SeamlessAccess service has been designed with privacy at its core. Despite that alignment on underlying values, the specific changes that browser vendors have been making (or planning to make) would come with unintended side effects for the SeamlessAccess service.
More specifically, the most significant change that browsers have been working on deals with how user information that is stored by one website can be read by another website, a mechanism that is called “third-party access”. This mechanism was under scrutiny because it can be exploited to track users across the web without their consent. However, it can also be used in ways that are entirely respectful of users’ privacy - and that is exactly how SeamlessAccess has been using third-party access to remember the user’s choice of institution between participating websites (see this blog post from the end of 2023 that explains in detail how SeamlessAccess uses third-party access). Without the ability for third-party access, SeamlessAccess can only remember the user’s choice of institute on individual websites. While that is still helpful to ease user’s access journeys, it is more limited in scope compared to being able to remember this choice across participating websites (a functionality that we refer to as ‘global persistence’).
Introduction of the Storage Access API
In an effort to develop more privacy-focused alternatives to third-party cookies, Google launched an initiative called the Privacy Sandbox. One of the new approaches developed within this program is the so-called Storage Access API which offers a mechanism for third-party access with much greater control in the hands of the user. A benefit of this technology is its cross-browser support; the downside is that the additional privacy safeguards would come with significant negative impacts in terms of user experience - including browser-mediated consent pop-ups that the user would need to frequently go through.
Despite those drawbacks, the Storage Access API offered SeamlessAccess a path forward to retain the ability to remember the user’s choice of institution across participating websites. Because of this, SeamlessAccess developed support for the Storage Access API and made this available for testing at the end of 2024. Following a round of testing, with great support from the community, support for the Storage Access API was rolled out in March of this year in preparation for the moment that third-party cookies would be retired for all users in Google Chrome and Chromium-based browsers.
And that is when Google announced that they would, after all, continue to support 3rd-party cookies without overhauling the associated user experience…
Implications of the April Google announcement
In an interesting turn of events, the team behind the Chrome browser announced in April that they were not going to follow the plan as originally set out: “… we’ve made the decision to maintain our current approach to offering users third-party cookie choice in Chrome, and will not be rolling out a new standalone prompt for third-party cookies.”
This announcement made us optimistic that it would allow SeamlessAccess to continue to offer global persistence without the strong UX downsides that we had been told would come with the Storage Access API. However, the announcement itself lacked technical detail to be sure about this interpretation. Since then, we have discussed this in detail with technical contacts at Google and have implemented additional tests which confirm that:
- The Chrome browser will still use the Storage Access API, as planned, but as a back-end technology that’s decoupled from the UX changes that were originally part of the scope;
- The Storage Access API will, by default, not require user consent and will not require the user to have visited the top-level domain (i.e., seamlessaccess.org). Users will have the option to switch on additional privacy controls that bring these requirements back;
- Through the Storage Access API, websites can access third-party information in a way that’s effectively unpartitioned, which is exactly what SeamlessAccess needs to deliver global persistence.
Note that the above holds for Google Chrome and other Chromium-based browsers like Microsoft Edge. Firefox has indicated that they will introduce the Storage Access API with privacy controls enabled by default, meaning that users will be prompted to provide consent and will need to have visited the seamlessaccess.org domain. (If the user does not do this, the fall-back behaviour is local persistence i.e. SeamlessAccess can still be used to remember the user’s choice of institute for the individual website).
For Safari users, we don’t expect global persistence to work because Safari still hasn’t said they will support the implementation pattern that SeamlessAccess is using - though that might change in the future.
What does that mean for researchers and scholars using SeamlessAccess?
For a researcher using Chrome with default settings: Use of the Storage Access API is enabled without the user having to adjust any settings. If the user visits a website and saves their choice of institute through SeamlessAccess, then this choice will be saved and visible when the user goes to another site that integrates with SeamlessAccess. No difference compared to the original SeamlessAccess experience.
For a researcher using Chrome with additional privacy controls enabled (opt-in setting): Assuming that the user has visited seamlessaccess.org, they will see a prompt asking them to allow sharing their information before the website is able to use the remembered choice of institute (see this blog post for an image of how that prompt would look like). This means that for this user, the SeamlessAccess button will be empty until they have clicked “allow”; thereafter the button will again show the user’s remembered institute.
For a researcher using Firefox (with the default “block 3rd-party cookies” setting enabled) or Safari: Storage Access API is not enabled, and SeamlessAccess will fall back to local persistence. That means that the user will still see their remembered choice of institute in the button for individual websites, but not between participating websites.
For a researcher using Edge: the user experience will be very similar to that in Chrome after support has been implemented (which is currently on our roadmap).
For a researcher using Safari: SeamlessAccess will fall back to local persistence, i.e. the user will still see their remembered choice of institute in the button for individual websites, but not between participating websites.
What does that mean for service providers integrating with SeamlessAccess?
SeamlessAccess has implemented the Storage Access API at the end of last year, which means that this new behaviour is already supported by the latest version of SeamlessAccess. That means that, for Limited or Standard Mode integrators, the only requirement is to use the most recent version of SeamlessAccess.
For Advanced Mode integrators:
- Please update to the most recent version of SeamlessAccess for your integration.
- If you would like to offer a path for Chrome or Edge users who choose to block 3rd-party cookies to go through a consent flow and remember their choice of institute, you need to update your code to expose a checkbox that’s served as an iframe from SeamlessAccess. (To be sure, this is not needed for users who are using Chrome or Edge with the default setting to not block 3rd-party cookies).
To wrap up…
We appreciate this has been a long read with a lot of information, but the overall take-away is this: SeamlessAccess will continue to be able to remember the user’s choice of institute across participating websites for Chrome and Edge users, with limited effort required for parties that integrate with SeamlessAccess.
Feel free to contact us with any questions through the usual channels (email or Slack).
3rd-Party Cookies and Storage Access API, Revisited, Once again
Last week’s announcement from Google
Last week, in an unexpected turn of events, Google announced that they have “made the decision to maintain our current approach to offering users third-party cookie choice in Chrome, and will not be rolling out a new standalone prompt for third-party cookies.” - in other words: Google will continue to support third-party cookies ‘as is’ for the foreseeable future, after all.
The recent announcement, entitled “Next steps for Privacy Sandbox and tracking protections in Chrome”, goes on to explain that work on the Privacy Sandbox initiative - which was conceived as a program to develop alternative solutions to 3rd-party cookies and other privacy-invasive browser functionalities - will not be halted, but that it “may have a different role to play in supporting the ecosystem” and that “[Google will] continue to work with the ecosystem on determining how these technologies can best serve the industry and consumers”.
This pivot comes at a time when many organizations, including SeamlessAccess, have prepared for the deprecation of third-party cookies in Chrome and other browsers. In particular, SeamlessAccess has implemented support for the Storage Access API - one of the technologies developed under the Privacy Sandbox - and is in the process of testing this implementation with a number of service providers that integrate with SeamlessAccess. One very attractive feature of the Storage Access API is its cross-browser support, which offers technical benefits as well as a consistent user experience across different browsers.
So, what does this announcement mean for SeamlessAccess?
The announcement is very high-level, and Google has so far not shared further details either publicly or privately. This means that questions remain about the exact feature set that Google will continue to support, and to what extent users would be able to (or expected to) protect their privacy through configuration settings. In addition, the future role of the Storage Access API and how other browser engines will respond to this pivot remains unclear. The Storage Access API was supported by all major browser vendors, and some browsers may decide to pursue this technology further.
From a SeamlessAccess standpoint, the most optimistic outcome would be that the SeamlessAccess service can continue to remember the user’s choice of institute across participating websites (“global persistence”) with additional privacy safeguards that are not as disruptive as those foreseen for Google Chrome’s implementation of the Storage Access API - but it is too early to say if that is indeed how things will play out.
For the moment, until we have a better grasp of the future relevance of the Storage Access API for different browsers, we don’t think it is right to ask you to invest more time and effort in testing. Hence we recommend pausing efforts to test SeamlessAccess’ Storage Access API implementation for the moment. We appreciate the support that you have shown in recent months, and we understand that teams have put significant effort into exploring this solution. Apart from its future place in SeamlessAccess’ technology stack, experimentation with the Storage Access API has helped us develop a much stronger understanding of user consent flows in a distributed environment. These findings will help us move forward with the service more effectively and provide us with a strong underpinning for future explorations to reduce SeamlessAccess’ reliance on 3rd-party cookies, whose support is fragmented and fragile.
We will follow up with a more detailed analysis as soon as possible.
Update: SeamlessAccess release on 12 March
Update: As communicated over Slack, the below release was rolled back because of unexpected compatibility issues for a small number of integrators. These issues have now been addressed and tested. We are releasing the new version of SeamlessAccess on Wed, 12 March.
Please note that this is a backward compatible change, also supporting the current SeamlessAccess implementation. As always, we will be closely monitoring the service before, during and after the release. If you experience any unforeseen behaviour, please alert us via Slack or email.
Upcoming SeamlessAccess release on 27 Feb
We will be releasing a new version of SeamlessAccess to production on Thursday, Feb 27.
This new version (link to GitHub) includes IdP filtering capabilities and support for the Storage Access API technology. Both of these changes have been tested over the last couple of months with several SeamlessAccess integrators, and we are excited to now bring these into the production environment.
Please note that this is a backward compatible change, also supporting the current SeamlessAccess implementation.
Advanced Mode integrators will be able to make the switch to Storage Access API at their convenience.
For Standard Mode integrators, we don’t expect the release will have an impact on user experience, except for users on Google Chrome who have either manually enabled “third party cookies phase-out” and/or have been enrolled into that program by Google. Such users may be presented with an additional consent screen by the browser. If so, they will need to grant such permission before they can benefit from SeamlessAccess’ capability to remember the user’s choice of institution across integrating websites.
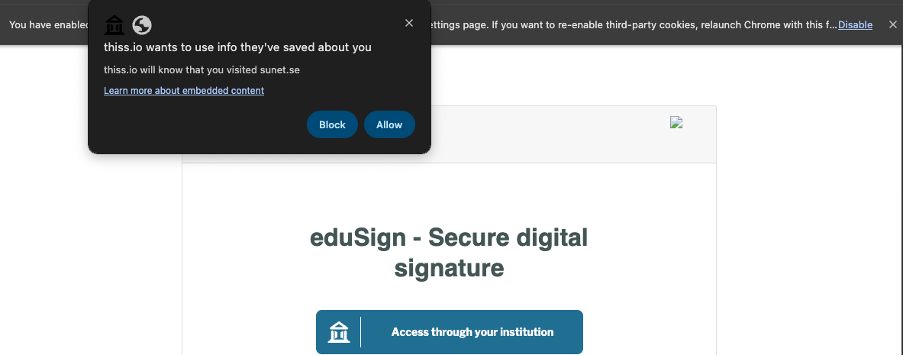
Above is a screenshot of how the browser consent screen is expected to look like (note: “thiss.io” will change to “seamlessaccess.org” after the release). We continue to be involved in further development of these features by the browser vendors.
For integrators that connect a Standard-Mode button to a third-party IdP discovery tool (sometimes referred to as ‘hybrid’ integration mode), we expect that the changes on the publisher side will be the same as for Standard Mode integrators, as described above. The third-party IdP discovery tool would need to make changes on their end to switch over to the Storage Access API implementation, just as is the case for Advanced Integrators. While we are working with relevant parties to design an optimal user flow for this integration pattern, we invite other service provides who uses this hybrid integration pattern to reach out and join the discussion.
As always, we will be closely monitoring the service before, during and after the release. If you experience any unforeseen behaviour, please alert us via Slack or email.
Please test: SeamlessAccess with Storage Access API (and an update from Google)
Migration to Storage Access API
As discussed in a string of blog posts last year, SeamlessAccess will be migrating to a new technology. This migration is needed in order to adapt to changes in how browser engines operate, in particular the deprecation of third-party cookies. If you are not familiar with this topic, we encourage you to read through the posts linked just above.
The new implementation makes use of a technology called Storage Access API that has been developed under the Privacy Sandbox initiative spearheaded by Google. Importantly, the Storage Access API is supported across browsers and will enable SeamlessAccess to continue to remember the user’s choice of institute across participating websites in a privacy-preserving manner - though the user experience will be somewhat different compared to the current implementation (which relies on third-party access to local browser storage). We will be following up with a separate post to talk more about the expected changes in user experience.
With this post, we are announcing that a (test) version of the SeamlessAccess service using the Storage Access API is now available for testing. We strongly recommend service providers that are currently integrating with SeamlessAccess to test and share feedback with us. We specifically urge those using the Advanced Mode integration pattern to test because the changes are expected to be the greatest for that pattern and development effort will be required to migrate to the new implementation. As a reminder, we strongly advise integrators to plan to migrate before the end of Q1.
How to test?
A test version of SeamlessAccess that uses the Storage Access API can be found here (see also this blog post for more detail about the various environments available for testing and integrations):
- Discovery service: https://use.thiss.io/ds/
- Persistence service: https://use.thiss.io/ps/
- Front-end code: https://use.thiss.io/thiss.js
Using SeamlessAccess with the Storage Access API feature will require some configuration. To accommodate the different integration patterns that service providers use, we have created a migration guideline which outlines how the new integration is done.
The guideline can be found under our documentation here: https://thiss-ds-js.readthedocs.io/en/stable/using-saa.html.
We welcome any feedback and questions that you may have, preferably over Slack. If you don’t have access to this channel, or would rather contact us over email, feel free to reach out to Hylke Koers (SeamlessAccess Program Director) at hylke@stm-solutions.org.
Integrator Workshop
We will be hosting another Integrator Workshop on Feb 4 to assist service providers that have integrated with SeamlessAccess with the migration process. If you’d like to join, and have not yet been invited, please contact hylke@stm-solutions.org.
News from Google: Storage Partitioning deprecation trial renewal
Under ‘related news’, Google has recently announced that they will renew their deprecation trial to “temporarily unpartition and restore prior behavior of storage, service workers, and communication APIs”. As a reminder, this trial allows participating services to continue to use unpartitioned storage in the browser, a feature that is critical for SeamlessAccess’ ability to remember the user’s choice of IdP across integrating websites in its current implementation (that is to say, without the Storage Access API technology discussed above). As with the previous extension, discussed in this post, only parties that are already enrolled will be eligible to take part in this extension. If you represent an organization that is currently taking part in ‘phase two’ of the deprecation trial, we encourage you to apply for this extension.
While this announcement, thankfully, provides a bit more time for parties to continue to use the current SeamlessAccess implementation to its full potential, it does not change the fundamental dynamics at play: 3rd-party access to cookies and local browser storage is being phased out and SeamlessAccess will be migrating to the Storage Access API in response to this change. In that light, as discussed above, we urge integrators to engage in testing, provide feedback, and plan development work as needed (for Advanced Integrators).
Coming up: Storage Access API and IdP filtering, ready for testing
As discussed in previous blog posts, see for example this post from 16 October, we are developing a version of SeamlessAccess that uses a new technology called Storage Access API. With this new technology, which is supported by different browsers, SeamlessAccess will continue to be able to remember and present the user’s choice of institute in the SeamlessAccess button. For the user this means that once they have located their home institute provider on one website, they can re-use that choice on the next website they visit and enjoy a much easier access experience.
We expect that this new version of SeamlessAccess will be ready for testing next week. We highly recommend all SeamlessAccess integrators to explore and test how this updated code integrates with your own environment. Testing can be done for both the Standard Mode and Advanced Mode integration patterns.
In addition to the migration to Storage Access API, this release will also include new functionality called “IdP filtering”, which enables service providers that use SeamlessAccess’ Standard Mode to customize the list of IdPs that is presented to their end-users in the IdP discovery (also known as “Where-Are-You-From” or WAYF).
For reference, the latest version of the SeamlessAccess code intended for testing and explorative work can be found here:
- Discovery service: https://use.thiss.io/ds/
- Persistence service: https://use.thiss.io/ps/
- Front-end code: https://use.thiss.io/thiss.js
Whereas the stable version of SeamlessAccess, which we recommend to use for production and production-like testing, is here:
- Discovery service: https://service.seamlessaccess.org/ds/
- Persistence service: https://service.seamlessaccess.org/ps/
- Front-end code: https://service.seamlessaccess.org/thiss.js
If you’d like to discuss the details of the release, you are welcome to join in on the discussion in our Slack channel. If you encounter any bugs or issues, the best place to post these is through Github.
A new chapter in the ‘browser changes’ journey: Preparing for the switch to Storage Access API
Over the last couple of years, we have posted regularly about changes that are being made to the way that browsers work and how those changes will affect SeamlessAccess (see e.g. this post from Feb 2024 or this post from Nov 2023 and references therein). These changes primarily impact SeamlessAccess’ ability to remember the user’s choice of home institute across participating websites, a functionality that we refer to as “global persistence”. That global persistence is one of the ways in which SeamlessAccess helps service providers to offer intuitive and, well, seamless access experiences to the research community. Since its development, SeamlessAccess has relied on third-party access to local browser storage as the technical capability to deliver that global persistence. (This mechanism is similar to third-party cookies and we’ll just use ‘third-party cookies’ as a short-hand in the rest of this post).
For a long time (see e.g. this post from 2021) browser engines have been planning to move away from third-party cookies because of user privacy concerns. And despite a recent announcement from Google suggesting a change of course, we continue to see steps being taken to limit the browser’s ability to store and make available data across different websites.
The path towards phase-out of third-party cookies has been hard to navigate at times, as browser vendors typically provide only limited information about specific steps and timelines. The same can be said about the development of new technologies that are meant to provide an alternative to third-party cookies. In the past, we’ve reported on FedCM, the Privacy Sandbox and, more recently, the Storage Access API.
We are now entering a new phase in this journey, one that thankfully comes with greater clarity. After intensive testing and discussions, the SeamlessAccess team has settled on adopting the Storage Access API as its new technology to store and retrieve the user’s choice of institute in the browser. One very important advantage of this solution is that it is supported by all major browser engines. While we are happy that this provides a clear path forward to retain global persistence, it should be noted that it will come with some changes to the user experience such as a consent step.
With that decision made, we are now planning for the transition process. For service providers that use the Limited or Standard Mode integration, we expect to be able to make the required changes entirely on the side of SeamlessAccess – meaning no development work for the service provider that integrates with SeamlessAccess. For Advanced Integrations the situation is different: Changes will be needed on both the SeamlessAccess side and on the the service provider side. SeamlessAccess will be developing documentation and guidance to assist with this process, and we will continue to engage with service providers to help them prepare.
For now it is important to be aware of timelines: SeamlessAccess will implement the Storage Access API before the end of this year (to work in parallel with the current implementation), and we strongly urge Advanced Integrators to reserve some development capacity to implement their part of the switch-over in the first quarter of 2025. Alternatively, Advanced Integrators could consider moving to the Standard Mode integration pattern.
We’re organizing an integrator workshop on 23 October to discuss the transition to the Storage Access API in more detail. If you represent a service provider that has integrated with SeamlessAccess, and you have not yet been invited to this workshop, feel free to send an email to hylke@stm-solutions.org and we’ll be happy to add you to the list (or get in touch with you separately).
Signed up for Google’s storage partitioning trial? Time to renew!
As we talked about in a post back in February “Calling all SeamlessAccess integrators to participate in deprecation trial for unpartitioned third-party storage” - and before that as part of a longer explanation back in 2023 - the team that works on Google Chrome has made available a limited-time trial that allows participating sites to continue to use unpartitioned storage in the browser. This is a feature that is critical for SeamlessAccess’ ability remember the user’s choice of IdP across integrating websites. The deprecation trial provides more time to implement new solutions as browsers are changing their default behaviour for users and become more restrictive about sharing information between different websites.
With the current trial coming to an end (today!), Google has announced that a new trial period will begin. However, in order to be part of the new trial you will need to renew your application! You can do that here.
We have worked with the Chrome team to collect answers to some of the questions that you may have at this point:
What happens if a site doesn’t renew?
The origin trial will officially stop working on September 3rd for any users on Chrome 111 to Chrome 126. Users who are already on 127 or 128 (current stable release) will see the default behavior already (that is to say, they will have partitioned 3rd party storage).
Is there a latest date a site needs to apply for renewal?
The Chrome team will review applications for the lifetime of the current origin trial, scheduled to be until March 2025 or thereabouts.
What will the experience be for different users (on different browser versions)?
If your site is part of the deprecation trial, and the user is using a Chrome browser of version 127 or later, then they will have the experience of the unpartioned storage that the trial promises.
If the user is using Chrome 111 to 126 then they will have partitioned 3rd party storage, i.e. the storage partitioning trial will not apply to those users.
When a user updates to Chrome version 133, or March 18th at the very latest, they will have partitioned storage.
What happens after this next trial ends?
The advice that the Chrome team gives is to plan for the future where no origin trials exist to support the legacy behavior. The outlook is clear: Partitioned storage is here to stay and will become part of the standard behaviour of all browsers in the future.
As we discussed in other blog posts (here and here), the SeamlessAccess team is working hard to test how emerging alternative technologies, in particular the Storage Access API, can be applied to power SeamlessAccess’ ability to remember the user’s choice of institute across different websites - which we know is a great piece of functionality to streamline to user’s access experience. We’ll keep you, and the rest of the community, updated through posts like these.
Google’s updated approach to third-party cookies: What does it mean for SeamlessAccess?
In a blog post that came out in April, we spoke about changes to browser technology and what impact those are likely to have on access experiences and SeamlessAccess. At the time, following Google’s communication on the subject, we worked under the understanding that Google would roll out deprecation of third-party cookies in Chrome to 100% by the end of this year.
Last month, Google announced a change of course. In an announcement on the Privacy Sandbox website they stated that “Instead of deprecating third-party cookies, we would introduce a new experience in Chrome that lets people make an informed choice that applies across their web browsing, and they’d be able to adjust that choice at any time. We’re discussing this new path with regulators, and will engage with the industry as we roll this out.” This update came as a surprise to many in our community, as well as to other sectors that are impacted by these changes such as online advertising.
The announcement is very high-level, and Google has not shared further details either publicly or privately - which makes it impossible to fully assess what this new approach will mean for SeamlessAccess. However, we do know that other browser engines such as Safari are no longer (by default) supporting third-party cookies. We also know that, if Google will leave third-party cookies as a choice to the user, a (presumably significant) portion of users will opt out. All of that is to say that third-party cookies (or, to be precise, third-party access to local browser storage) will in the future only work for some users and for some browsers. This is in stark contrast to the essentially universal mechanism that third-party cookies once offered for SeamlessAccess to store the user’s remembered choice of institute.
SeamlessAccess is all about delivering a consistent and reliable user experience to ease access pathways to scholarly resources. The kind of fragmentation and inconsistency described above is clearly at tension with that ambition, and so we will continue to explore alternative technologies – such as the Storage Access API – that have the potential to let SeamlessAccess persist the user’s choice of remembered institute in a consistent, easy-to-use, and privacy-respecting way across different browsers. Google’s recent announcement means that there is more time to develop and test such new technologies before the current SeamlessAccess implementation will break, but it is also likely to introduce additional complexity to a future solution.
As we continue to move in this direction, our previous recommendations for Service Providers that integrate with SeamlessAccess still hold:
- We highly recommend that you participate in Google’s deprecation trial for unpartitioned third-party storage to keep the SeamlessAccess ‘smart button’ working for your users.
- If you use the SeamlessAccess Advanced Mode integration, we recommend that you consider switching to the Standard Mode integration because that integration pattern will be significantly more robust under changes in browser technology.
Finally, we recognize the communications challenge that our community faces to navigate this ongoing period of uncertainty that is driven by agendas essentially external to us. From the SeamlessAccess side, we will continue to engage with browser vendors and publish posts like these where we share our findings and perspectives. Additionally, we have set up a Slack channel to facilitate dialogue and knowledge exchange at a technical level between SeamlessAccess and parties that integrate with SeamlessAccess about these topics. If you represent a service that is integrated with SeamlessAccess, and are interested in joining this channel, please email Hylke Koers at hylke@stm-solutions.org.
Important update for all SeamlessAccess integrators regarding the impact of browser changes.
Today’s post updates the evolving story about changes to browser engines and how those changes affect SeamlessAccess. Perhaps the most visible change in this context is the deprecation of third-party cookies by Google Chrome, which has already been rolled out to 1% of users and that will be ramped up “to reach 100% of Chrome clients by the end of Q4, subject to addressing any remaining concerns of the CMA.”, as stated on the Google Developers Blog
Before we dive into updates and our recommendations, a reminder from last month’s post: If you are a service provider that integrates with SeamlessAccess, we highly recommend that you participate in Google’s deprecation trial for unpartitioned third-party storage to keep the SeamlessAccess ‘smart button’ working for your users.
Testing new technologies
In last month’s post, we explained that SeamlessAccess is actively prototyping and testing alternative technologies, such as FedCM, CHIPS, and the Storage Access API, which are designed to fill some of the functional gaps that will be left after the deprecation of third-party access to cookies and local browser storage. As a reminder, this is important for SeamlessAccess because we use local browser storage to remember the user’s choice of institution across participating websites and service providers. (See here for more details, an introduction, and links to further information).
From the technologies mentioned above, our tests suggest that the Storage Access API is the most promising option. It appears to be designed for exactly the kind of use case that SeamlessAccess is all about: Storing certain information about the user in a way that respects user privacy and that delivers direct value to the user by supporting a more consistent and intuitive user experience. Unlike FedCM, it is also implemented across all major browsers.
While it is important to realize that these technologies are under active development, with several improvements and extensions underway, our current testing suggests that:
- SeamlessAccess can use the Storage Access API for the Limited and Standard mode integration patterns, including the SeamlessAccess ‘smart button’ (which shows the user’s last choice of institute directly in the button) – however with some additional steps that the user will need to take, in particular providing consent when the website first wants to retrieve information through the API.
- The current implementation of the Storage Access API does not provide a ready-to-go alternative for the Advanced integration mode. (This is because the Storage Access API is designed for scenarios where functional components are embedded in iframes, which are used for the Standard integration mode but not for Advanced).
As mentioned before, this is a rapidly evolving space and there are suggested extensions to the Storage Access API that may be used to power the Advanced integration mode – however, as of today, these are not widely supported and untested. We also note that Advanced integrators may still be able to locally remember the user’s choice of institute, though that possibility will likely be dependent on the user’s choice of browser and their configuration settings, and needs further testing.
What does this mean for parties that integrate with SeamlessAccess?
If you use the SeamlessAccess Standard or Limited mode integration, we recommend no changes to your current implementation at this point – though be advised that users may experience seeing a SeamlessAccess button without their choice of remembered institute more often than they are used to (depending on their choice of browser and other specific context), so we recommend to prepare for user support queries.
If you use the SeamlessAccess Advanced mode integration, we recommend that you start preparing for alternatives and mitigating actions such as switching to the Standard mode integration. To be clear, we will continue to drive for and test new technologies that can continue to power the SeamlessAccess Advanced mode – but at this point in time, it is uncertain if and when these will become available.
It should be emphasized that the area of risk is focused on ‘global persistence’ i.e. the ability to store and share the user’s last choice of institute between different websites that integrate with SeamlessAccess. While this information is very valuable to deliver a seamless user experience, it is not part of the critical path for a user to log in via federated authentication. In other words: Even in a scenario in which global persistence would break completely, users will still be able to gain access via federated authentication. Also, the central SeamlessAccess IdP discovery service will continue to work and will be able to remember the user’s choice of IdP (because this is first-party access). And, as noted above, Advanced integrators may still be able to remember the user’s choice of institute on their own site, though the specifics of this will likely be browser-dependent and require further testing.
SeamlessAccess will continue to test new technologies as they become available, and we’ll keep the community updated via posts like these. Additionally, we are setting up a Slack channel to facilitate dialogue and knowledge exchange at a technical level between SeamlessAccess and parties that integrate with SeamlessAccess about these topics. If you represent a service that is integrated with SeamlessAccess, and are interested in joining this channel, please email Hylke Koers at hylke@stm-solutions.org.
Calling all SeamlessAccess integrators to participate in deprecation trial for unpartitioned third-party storage
In a blog post published towards the end of last year, we spoke about an update to Google’s Chrome browser that by default enabled a new feature called Storage Partitioning. This feature effectively blocks third-party websites from accessing information held in the local browser storage, which is used by SeamlessAccess to show the user’s remembered choice of institute in its button. This specific change is an example of a broader-scale and ongoing journey by the main browser vendors to deprecate functionalities that can be used to track users on the web. In that process, however, also non-privacy-invading use cases are impacted including access to scholarly resources through SeamlessAccess.
We also described in that blog post how individual users are able to restore the SeamlessAccess button by opting out of this feature, and we continue to recommend this practice.
In addition to this option, which requires individual users to take action, Service Providers that integrate with SeamlessAccess are also able to opt out of the Storage Partitioning setting in Google Chrome without placing the burden on their end-users. This can be done at the level of the website, following these instructions from the Privacy Sandbox: Participate in deprecation trial for unpartitioned third-party storage, Service Workers, and Communication APIs.
This approach has been tested and validated by Atypon, who have implemented it to ensure SeamlessAccess continues to work as intended across several of the publishing domains which they host. Olly Rickard, Product Manager, confirmed: “By taking part in this deprecation trial, we are able to continue to provide our customers with the SeamlessAccess user experience which they trust and value until at least the end of this trial. The process to make use of this option was very straightforward and I highly recommend other parties that have integrated with SeamlessAccess to do the same.The more people that sign up, the more sites can share the remembered institute, the more valuable the feature is for our community”.
While this is good news for the moment, the deprecation trial is time-bound and currently set to expire on September 3rd with the release of Chrome 127. The SeamlessAccess team, together with several of partner organizations, is working hard to explore a number of alternative technologies such as FedCM, CHIPS, and the Storage Access API. These technologies have been made available by Google and other parties - in some cases very recently - to offset some of the impact of upcoming browser changes for use cases such as access and authentication. Some of these should work across browsers, offering a more standardized solution, while others are more specific to Google Chrome and browsers that use the same code-base (such as Microsoft Edge). We’re eagerly testing all options to learn if they are able to provide an alternative solution for SeamlessAccess’ function of remembering the user’s last choice of institute across participating websites and scholarly resources.
This is a very dynamic space, with lots of change happening in sometimes parallel tracks. To navigate those changes, we are stronger together. If your organization is already experimenting with the above technologies, has learnings to share, or would like to contribute - we’d love to hear from you!
Third-party cookie deprecation and its effect on SeamlessAccess
Is your SeamlessAccess button acting weird? Not showing your remembered institute as you expect? This might be due to a new browser configuration setting that blocks third-party cookies. Without those cookies, the SeamlessAccess button (i.e. “Access through..”) will work differently than you might expect - but the other SeamlessAccess services (login, discovery, remembered choice on the discovery page) continue to work as before. And you can fix the button, too! (at least for now)
What’s the situation?
Late October, Google released version 118 of its Chrome browser. This version enables a feature called Storage Partitioning by default. This feature prevents third-party cookies from being used in the traditional sense, which impacts - among many other services on the web - the SeamlessAccess button. You can read more about this specific feature in this post by Google.
This is a recent, and very visible, example of a broader trend with browser vendors making changes to how browser engines work in order to prevent unsanctioned tracking of users across the web - which will also impact access experiences on the scholarly web. This has been covered in several earlier SeamlessAccess presentations and blog posts (see e.g. this blog post from July and references therein).
What to do about it?
There is a temporary solution to continue third-party cookie support for Chrome users. This is said to be supported until September 2024.
The solution is presented by Google as a set of instructions for the user and for the service provider. As a user, you can toggle off Storage Partitioning in Chrome (version 118 or higher):
- Type ‘chrome://flags/#third-party-storage-partitioning’ into your browser’s address bar (note: start with ‘chrome:', not ‘http:’ or ‘www ' as you would normally do)
- Disable the “Third-party Storage Partitioning” flag.
(More information can be found here)
As a service provider, you can follow this guide to enable a (temporary) solution.
Background
For a number of years, the tech industry has been targeting third-party cookies. Driven at least in part by fortified legislation around user privacy (e.g. GDPR in Europe), browser vendors are progressively working to change features that may be used to track users across the web and, in some cases, proposing their own solutions instead.
For many years the browser highlighted how cookies are stored and used and made it possible for the user to opt out of third party cookie use. In the last couple years, several browsers have set third-party cookie support to opt in. The most recent to follow this path is Google Chrome which, in its latest build, requires the user to effectively opt in for third-party cookies to be stored and used.
To be clear, the opt-in pattern means that the browser will not support third-party cookies unless the user explicitly configures the browser to do so. And, even for users who want their browser to support third-party cookies, this is not always an easy thing to do. To understand why all this matters to SeamlessAccess, Let’s talk about how SeamlessAccess uses these cookies to create a ‘smart’ access button.
The smart button - presenting an actionable option
SeamlessAccess is a discovery service* with extra everything: Easy to set up and start using on the service side, a standard version that’s great out of the box and support for customisation where needed, an accessible interface (WCAG 2.x) with an emphasis on user-friendly flows proven through extensive user testing.
*) beyond the actual service, we are also very much involved with the community and industry as a whole to make sure our user base login is covered also in the future.
Part of what makes the federated user access journey so appealing through the SeamlessAccess service is that we’re able to populate the SeamlessAccess button with the user’s last used identity provider. This looks something like “Access through SUNET” (SUNET being an example of an Identity Provider that will be recognized by its users) - which immediately makes the button recognizable and trusted. If, on the other hand, no previous choice was made the button instead displays “Access through your institution”.
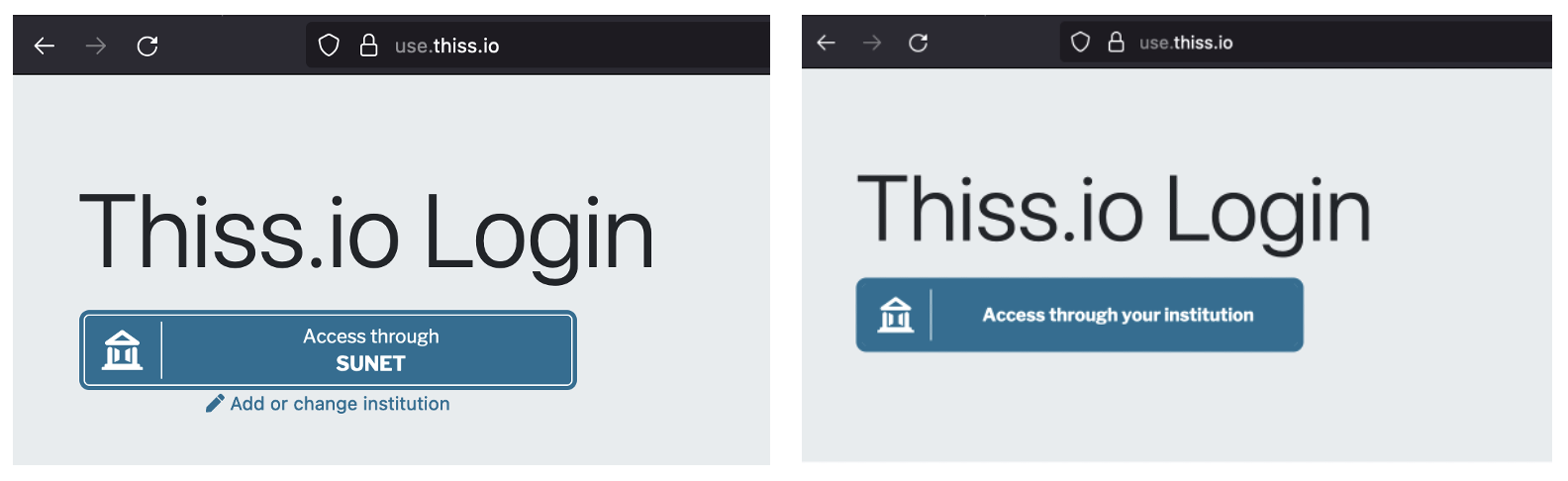
Because of how we are displaying the user’s identity provider in the button, and thus on the frontpage of many scholarly online resources, the button is immediately recognizable, clear and actionable for the end-user.
Up until now we’ve even been able to populate the Access button with e.g. “Access through SUNET” even the first time a user visits a new website. How? Through the use of a feature called “Local Browser Storage” which allows third-party websites to read and write information. Note that Local Browser Storage and cookies are technically somewhat different features - and there is a possibility that browsers will at some point treat third-party access to Local Browser Storage and to cookies differently - but for most practical purposes the restrictions that browsers are now imposing on cookies apply to Local Browser Storage as well. (Because of this, and for the sake of readability, we will in this post sometimes hand-wavingly use the word ‘cookie’ to refer to the information that SeamlessAccess stores in Local Browser Storage).
Note that this does not mean that SeamlessAccess is not respectful of the user’s privacy - quite the opposite! SeamlessAccess uses the remembered institute in a very user-privacy friendly manner: the fact that the user has data from “SeamlessAccess” in their Local Browser Storage only means that they have at some point used a service that integrates with SeamlessAccess as a federated discovery service, but it does not point back to any service in particular; it could be any number of the hundreds of services (or even thousands; we specifically don’t track exactly where SeamlessAccess is used). And SeamlessAccess does not track anything about how the service is used. In fact, it could well be argued that, if instead of a single third-party ‘cookie’ we would use first-party ‘cookies’ to save the user’s previously visited sites and services in the users browser, then the use of our service would leave a trail in the browser which someone could read and figure out which services the user has accessed - which would clearly be a much greater breach of privacy.
In summary, SeamlessAccess has taken the appropriate route to preserve user privacy while enabling a user friendly access journey. However, because the same technology is used to track users in other use cases we are seeing the kind of impact that is described here on the SeamlessAccess button.
In conclusion...
This means (at least for now) that, going forward, the SeamlessAccess button will behave in one of three ways:
- It displays the users previous identity provider inside the button, e.g. “Access through SUNET” even if it’s the first time a user is visiting that service.
- It only displays the identity provider inside the button if the user has previously visited that site and chose an identity provider, i.e. “Access through your institution” the first time and thereafter e.g. “Access through SUNET”.
- The button does not display the previous identity provider choice, i.e. it will always show “Access through your institution”.
These behaviours are dependent on browser, browser version, browser engine and specific user and service settings - which means that it won’t always be obvious to the user (or to someone running a service) why a specific type of behaviour is observed. However, if your browser since recently is presenting the SeamlessAccess button differently then what you are used to, it might be because a recent upgrade is now blocking SeamlessAccess from accessing its cookie!
As communicated in presentations and blog posts before, we are working with browser vendors and the industry at large to future-proof SeamlessAccess.
Links about the future of third party cookies, and option to opt-in for Chrome
As previously mentioned, many browsers already use opt-in for third party cookies, and we’ve talked about them in previous blog posts and videos (see e.g. this blog post from July and references therein). So here is the latest change, which is for Chrome.
Google Chrome
-
“To prevent certain types of side-channel cross-site tracking, Chrome is partitioning storage and communications APIs in third-party contexts." - describes how the user can enable and disable Storage partitioning (i.e. third party cookie support): https://developer.chrome.com/en/docs/privacy-sandbox/storage-partitioning/
-
“Preparing for the end of third-party cookies”: https://developer.chrome.com/blog/cookie-countdown-2023oct/
-
“Storage partitioning” enabled by default since Chrome 117/118: https://developer.chrome.com/en/docs/privacy-sandbox/storage-partitioning/
-
“Participate in deprecation trial for unpartitioned third-party storage, Service Workers, and Communication APIs”: https://developer.chrome.com/en/blog/storage-partitioning-deprecation-trial/
We will continue to post updates, so please check our website regularly or subscribe to our mailing list.
(shout-out to the colleagues at Atypon for providing the links to the recent Google changes)
FedCM: July update on the efforts between the R&E community, the web community, and browser vendors
This is an update following continuous meet-ups and other gatherings between representatives of the Research & Education (R&E) community and the browser vendors – discussing what capabilities in and around FedCM are required for our community to continue to serve academic users and their use cases.
Background
In a blog post titled “An emerging new technology for federated access: Federated Credential Management (FedCM)” and several later blog posts (most recent, previous), videos (one, two) and FAQs (for librarians and publishers), we discussed ongoing developments at the major browser vendors that are bound to have a significant impact on how users will experience the web in general, and on federated access in particular. To recap, these changes are driven by concerns around user privacy - including regulations such as GDPR - and meant to stop the unsanctioned tracking of users across the web.
“Why is that relevant to federated access?”, you might ask. Well, the complicating factor is that some browser functionalities that are used to track users, for example third-party cookies, are also used to support federated access - and the browser has no way to tell the difference! This means that, in an effort to improve user privacy, current access solutions for scholarly resources on the web may no longer work in the way they used to.
This is, in fact, already happening today with IP-based access: Apple has started to hide IP addresses by default for certain users, which means that these users may suddenly find themselves unable to access research publications or other scholarly resources if their library relies on IP authentication to provide access (see “Apple’s iCloud Private Relay impacting IP recognition” in our August 2021 newsletter). It also is affecting the implementations of SeamlessAccess as they exist today, with the experience of persistence (a remembered choice of institution) becoming dependent on which browser is being used – but it is yet to have an effect on the core functionality of discovery and authentication.
Recent developments at browser vendors
Google (Privacy Sandbox), Apple (one, “blocking known tracking query”) and Mozilla (one, two, three) have introduced either timelines for implementing, or already implemented, changes that affect third party cookies, IP-authentication and potentially the SAML-protocol.
In particular, Google has announced that they will disable third-party cookies for 1% of Chrome users in Q1 2024.
Mozilla has now included FedCM as part of their developer versions of the Firefox browser. And, in part through our efforts, Google is looking to put together an easy way for service providers to test how their service would work with the current FedCM profiles.
Help us test FedCM
In a lightning talk (starting at minute 27:30) at the TNC23 conference organized by GÉANT, Zacharias Törnblom (Product Manager for SeamlessAccess) issued a call to the community to help test the features in FedCM with their use case and report back to the GitHub repo for FedCM. This remains the best way for our community to help shape the browser changes to something that works for us.
New resources available
Several new resources have been created to you may find helpful to better understand the issues and their likely implications:- “REFEDS Community Chat: Federated Identity and the Browser Update” - a new video by REFEDS that can be used as an introduction to the subject of how this affects the R&E community.
- Representatives from two National Research & Education Networks (NRENs), Canary (Canada) and JISC (UK), put together a test service with FedCM and explain it in this video.
We would suggest visiting and following the REFEDS group “Browser Changes and Federation”, specifically the page “State of browser privacy evolution” where the current known actions taken by browser vendors alongside their adverse affect on R&E technology is listed.
And, as always, you can read up more in the W3C group, and the REFEDS group (also mentioned above) that has been formed to keep the community informed and educated about what the new landscape looks like. If you would like to join in on the conversation then you can find more information on the W3C website. The resources for the proposals can be found in the project’s GitHub, and the discussions around it can be accessed through the mailing list of the W3C community group and the mailing list of the REFEDS group for browser changes.
We will continue to post updates, so please check our website regularly or subscribe to our mailing list.
FedCM: An update on the efforts between the R&E community and browser vendors
This is an update following a recent meet-up between representatives of the Research & Education (R&E) community and Mozilla and Google – discussing what capabilities in and around FedCM are required for our community to continue to serve academic users and their use cases. Note: SeamlessAccess is organizing a more in-depth webinar on this topic on April 6 - register here!
Background
In a recent blog post called “An emerging new technology for federated access: Federated Credential Management (FedCM)” and several earlier blog posts, videos (one, two) and FAQs (for librarians and publishers), we talked about ongoing developments at the major browser vendors that are bound to have a significant impact on how users will experience the web in general, and on federated access in particular. To recap, these changes are driven by concerns around user privacy - including regulations such as GDPR - and meant to stop the unsanctioned tracking of users across the web.
“Why is that relevant to federated access?”, you might ask. Well, the complicating factor is that some browser functionalities that are used to track users, for example third-party cookies, are also used to support federated access - and the browser has no way to tell the difference! This means that, in an effort to improve user privacy, current access solutions for scholarly resources on the web may no longer work in the way they used to.
This is, in fact, already happening today with IP-based access: Apple has started to hide IP addresses by default for certain users, which means that these users may suddenly find themselves unable to access research publications or other scholarly resources if their library relies on IP authentication to provide access (see “Apple’s iCloud Private Relay impacting IP recognition” in our August 2021 newsletter). It also is affecting the implementations of SeamlessAccess as they exist today, with the experience of persistence (a remembered choice of institution) becoming dependent on which browser is being used – but it is yet to have an effect on the core functionality of discovery and authentication.
Update
In early March, representatives of SeamlessAccess and other organisations representing the R&E community met up with developers from Google and Mozilla in Mountain View.
The meeting started with the research community describing our use cases, the technology that makes access on the scholarly web work today, and detailing examples of how federations are run and maintained. After this introduction to the R&E space, we dug in on what changes the browser vendors are looking to achieve and how those changes would rhyme with academic requirements and use cases, in particular with the established multilateral trust between parties in R&E federations. SeamlessAccess was received very positively and used as a reference for a good IdP discovery implementation throughout the conversation.
The outcome of the two days are two proposals that are publicly available (links below). Both of these proposals provide a context in which SeamlessAccess can continue to function and play an important role in providing researchers with powerful and easy-to-use access flows.
The two proposals are different in the levels of engagement and complexity for both identity federations and browsers. One proposal (link to GitHub) is centered around explicit user consent to establish a local connection (cookie) between the user’s chosen institution (IdP) and the relying party (SP). The other proposal (link to GitHub) consists of browsers using the trust established inside the federation context to allow for the user to flow more freely between vetted IdPs and SPs using the federation’s metadata as a guiding tool.
Work on elaborating these proposals will likely continue over the course of the year, and SeamlessAccess will continue to be heavily engaged in this. Both in the W3C group, and the REFEDS group that has been formed to keep the community informed and educated about what the new landscape looks like. If you would like to join in on the conversation then you can find more information on the W3C website. The resources for the proposals can be found in the project’s GitHub, and the discussions around it can be accessed through the mailing list of the W3C community group and the mailing list of the REFEDS group for browser changes.
We will continue to post updates, so please check our website regularly or subscribe to our mailing list.
An emerging new technology for federated access: Federated Credential Management (FedCM)
In earlier blog posts, videos (one, two) and FAQs (for librarians and publishers), we talked about ongoing developments at the major browser vendors that are bound to have a significant impact on how users will experience the web in general, and on federated access in particular. To recap, these changes are driven by concerns around user privacy - including regulations such as GDPR - and meant to stop the unsanctioned tracking of users across the web. “Why is that relevant to federated access?”, you might ask. Well, the complicating factor is that some browser functionalities that are used to track users, for example third-party cookies, are also used to support federated access - and the browser has no way to tell the difference! This means that, in an effort to improve user privacy, current access solutions for scholarly resources on the web may no longer work in the way they used to. This is, in fact, already happening today with IP-based access: Apple has started to hide IP addresses by default for certain users, which means that these users may suddenly find themselves unable to access research publications if their library relies on IP authentication to provide access (see ‘Apple’s iCloud Private Relay impacting IP recognition’ in our August 2021 newsletter).
This blog post is about a new piece of technology that has the potential to support federated access: Federated Credential Management (FedCM), described on the Chrome Developers Privacy Sandbox page as “A web API for privacy-preserving identity federation.” Originally developed by Google, this technology seems to have now gathered the support from other major browser vendors, including Apple and Mozilla, and is thus emerging as a front-runner to fill the gap that will be left by the deprecation of third-party cookies and other tracking-like functionalities.
FedCM is under active development, and questions remain to what extent it will be suited to support scholarly and academic use cases that are today served by federated authentication technologies and by SeamlessAccess. Just to give one example, it is not uncommon for researchers to have to find their home institute from a list of several tens of thousands of choices (a challenge that is the very raison d'être for the SeamlessAccess central IdP discovery service). This is a fundamentally different order of magnitude compared to the choice of a few social web logins, which calls for a different approach to support the user in their access journey.
In light of these questions and concerns, SeamlessAccess is an active contributor to work that is currently taking place under the auspices of the W3C Federated Identity Community Group. The purpose of this work is to foster an active dialogue between browser vendors and the research community to ensure that researchers’ use cases are understood and taken into account as FedCM is further designed and developed. An upcoming milestone is an info-sharing event at the end of February that will bring together developers from Google and technologies like Shibboleth, SimpleSAMLphp, and SeamlessAccess. We believe that this is going to be a great opportunity to ‘get our hands dirty’ with FedCM in its current state and understand how it can support researchers’ access needs. Equally, we look forward to sharing our insights into user needs and the approaches that we’ve developed to inform the core FedCM team on how FedCM could benefit the research community.
We will be reporting back to the SeamlessAccess community after the event, so please check our website regularly or subscribe to our mailing list to receive updates.
Contract Language Model License Agreement 1.0
The Contract Language Working Group is pleased to release the Federated Authentication Contract Language Model License Agreement 1.0. From the introduction:
“Existing contract language between resource providers and libraries is almost universally focused on authentication and authorization via IP address. Reference to federated access is most often with language that refers to “secure networks”, and the authorization of users that are on said network to access resources. As more and more resources move to federated access, this language is no longer sufficient. Users will instead be on various local networks (home, coffee shop, etc.), and will no longer be proxied ‘into’ the organization’s network in order to achieve access to resources. Therefore, contracts will need to begin to take into account federated access more explicitly with new language specific to the nature of federated access and recent developments around it.”
There are two documents that the Working Group would like to provide as a part of this release. The first is the Model License itself, a version of the Library Model License Agreement 5.0 from the Center for Research Libraries which was edited to provide federated authentication specific language where needed.
Federated Authentication Contract Language Model License Agreement 1.0 https://docs.google.com/document/d/1scLrPQMDTtl4j7F7oqnQCPPQFBa2IB9P8dlJe2XYDUs/edit?usp=sharing
The second is a document with only the altered language, pulled out of context of the license as a whole, but perhaps more useful for those libraries who have existing license language they would prefer to continue to use. With this, those libraries could borrow language where necessary without needing to incorporate the entirety of a new license.
Seamless Access Model License Language - Isolated FedAuth Language https://docs.google.com/document/d/1d7TFFphRlKwAE3CsvGBtiS7s2XVcPD4fr1PaJV6Ikt4/edit?usp=sharing
This MLA builds on the earlier work of this group to provide Entity Category Use Case Scenarios for libraries and publishers to use when determining which attributes should be shared during federated authentication.
The goal of this work is to provide libraries and publishers common language to use in license agreements, and we hope that it makes the process of making user access to remote resources via federated authentication easier to implement for everyone. If you have any questions about this document, feel free to contact the chair of the working group, Jason Griffey.
The Working Group would like to acknowledge that much of the feedback from the library community revolved around the need for privacy-specific language updates throughout the broader, unchanged license text. We agree that a language review along that front is warranted, but this working group was focused on the federated authentication aspects of the license. We feel that those aspects are strongly privacy-preserving when implemented as outlined. We strongly encourage a privacy-focused library group to review the underlying license document to bring it into line regarding privacy best practices, and would gladly update our version of the license here when that review becomes available.
The Challenges around Where-Are-You-From (WAYF)
There are many ways to manage access to remote resources. From the use of IP addresses via VPN or proxy services to federated identity, the goal of enabling access to remote content is both easier and more complicated than ever before.
A common element in federated access workflows is that, at some point in their journey, the user needs to select the institution they want to use to authorize their access. When the institutional name is clear and unambiguous, users will have no problem selecting their institute from a multitude of other choices. However, that clarity is not always the case: in some situations the user is presented with a number of options with identical or very similar names, which makes it difficult and frustrating for them to choose the institute that grants access to the resource they are looking for. This is a thorny usability problem known as WAYF (‘Where Are You From’) Entry Disambiguation.
Recommendations and free Webinar
To address this challenge, SeamlessAccess started a Working Group to analyse the situation and present actionable recommendations for the various stakeholder groups. This work has now completed, and we’re happy to share the recommendations coming out of this Working Group in a webinar on October 26. The webinar is free of charge, please register here.
If you’re interested in reading more about this issue, please visit the Learning Center or jump straight to the recommendations.
Note: Going forward, we will be sending out this newsletter on a bimonthly schedule.
Events
Just before the summer period, SeamlessAccess was discussed in a number of events and conferences. In case you missed it, slides and recordings are available:
- “What’s new with SeamlessAccess?” webinar (May 24), hosted by the STM Association. A recording is available here.
- SeamlessAccess was one of the services discussed in the “Access and Assessment: Delivering Privacy Preserving Services” session at NASIG 2022 (June 7), a session that focused on protecting user privacy while delivering seamless user experiences. Slides are available here.
- Tim Lloyd, Heather Flanagan and Todd Carpenter delivered an overview of the current state and upcoming challenges in access mechanisms at the 44th annual SSP meeting (June 3). You will find the slides here.
Here are some upcoming events where SeamlessAccess will be presented as we head towards the fall:
- 14 Sept: Presentation about SeamlessAccess at the “Trust and Identity” track of the 31st NORDUnet Conference, focusing on value for federation operators.
- 18 Oct: Frankfurt: SeamlessAccess will be one of the services discussed during a panel session about “New Collaborations” at the 2022 STM Frankfurt conference.
- 2-4 Nov: Charleston Conference. SeamlessAccess will be featured in a session called “In It Together: Bold New Collaborations for Researchers and Publishers” - more details to follow!
Also, Heather Staines will be attending the ALPSP annual conference (14-16 Sept) and the SSP New Directions Seminar (Sept 21-22) - don’t hesitate to say hi when you’re there!
WAYF Entry Disambiguation recommendations
We’re happy to report that the WAYF Entry Disambiguation Working Group, which we introduced in last October’s newsletter, has finalized its recommendations. This Working Group has looked at an important usability challenge in federated authentication, namely when different identity providers (IdP) present themselves with identical, or very similar, names to the end-user - which is a well-known source for confusion and broken user journeys.
GIven the significance of this problem, we are very glad that the Working Group has now delivered recommendations for institutions, federations and other stakeholders to address this problem. You will find the recommendations here (PDF doc) or here (HTML, including recommendations together with the earlier ‘challenges’ white paper).
Advanced Integrator workshop
At the end of June, we organized a workshop for Advanced Integrators to discuss the expected impact of upcoming changes to browser technology, in particular changes that will break current mechanisms for third-party access to cookies and other information held by the browser. The workshop provided valuable insights into how services are using the Advanced Integration pattern today, and how the different organizations are preparing for the upcoming changes in the face of many uncertainties.
If you find yourself wondering “what browser changes?”, we’d highly ecommend checking out these references:
- “Web browsers, privacy, and your publishing platform webinar” (webinar)
- “Web browsers, privacy, and federated identity” (blog post)
- “FAQ on Browser Privacy Changes and Library Resource Access” (FAQ)
In addition, the W3C Federated Identity Community Group, who offer a forum to discuss incubating web features that will both support federated identity and prevent untransparent, uncontrollable tracking of users across the web, recently published a draft report.
SeamlessAccess will continue to monitor and update stakeholders as the situation unfolds.
Cambridge University Press and De Gruyter join SeamlessAccess
SeamlessAccess continues to grow with two additional academic publishers implementing the service: Cambridge University Press and De Gruyter.
Cambridge University Press has integrated SeamlessAccess with their Higher Education platform. Peter White, Digital Partnerships Manager, explains: “The implementation of the SeamlessAccess button on the Higher Education login page is the latest step in a programme of development from Cambridge that aims to transform the experience of end-users of Shibboleth-based institutional authentication. Back in March we released a new Discovery Service – or WAYF (‘Where-Are-You-From’) display – designed to speed up and improve the authentication journey of end-users who choose to start the institutional login process on either Cambridge Core or the Higher Education website.” In the coming months, Cambridge University Press will add the SeamlessAccess button to Cambridge Core, accelerating access to more than 1.8 million journal articles and more than 46 thousand monographs and other books.
De Gruyter, an independent academic publisher disseminating excellent scholarship since 1749, has completed an Advanced Integration on their platform degruyter.com. “De Gruyter is excited to now provide our customers with an easier login experience through SeamlessAccess. With the help of LibLynx, who provide our authentication and identity management system, we have integrated SeamlessAccess and now show the SeamlessAccess button on our WAYF page and on all product pages. This integration also gives us more control of the institution names as they appear in our institution selector, which helps our customers finding the correct entry for their login”, says Ulrike Engel, Product Owner Delivery Platform at De Gruyter.
We’re excited to have these two publishers joining SeamlessAccess!
Welcome, Bojhan and Zacharias
SeamlessAccess has two new team members: Bojhan Somers (UX) and Zacharias Törnblom (Product Manager).
Bojhan joins the team as User Experience Designer. He brings many years of experience in academic publishing as well as working with (open-source) communities. He is passionate about bringing simplicity to complex design challenges, and eager to apply that passion to SeamlessAccess.
Zacharias joins SeamlessAccess as Product Manager with a background in the public transportation sector, where he has been managing end-user facing products with a focus on accessibility, usability and privacy. Upon joining, Zacharias noted, “I’m impressed by the ease of use with SeamlessAccess, and excited for the coming changes we have planned. These will make the SeamlessAccess-button easier to implement and maintain and will grant users access whether their login method of choice is through a federated institution or a non-federated service.”
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Events
We have several events coming up where you can learn more about SeamlessAccess and have an opportunity to interact with the team:
- “What’s new with SeamlessAccess?” webinar (May 24), hosted by the STM Association. Register here to learn more about SeamlessAccess, our roadmap, and experiences from Emerald Publishing, who have integrated SeamlessAccess onto their Emerald Insight platform last year.
- SeamlessAccess will be one of the services covered in the “Access and Assessment: Delivering Privacy Preserving Services” session at NASIG 2022 (June 7). The session will focus on protecting user privacy while delivering seamless user experiences. You can register for NASIG here.
And a reminder for two other upcoming opportunities where you can meet us in person:
- Council of Science Editors meeting, May 1-3 in Phoenix, AZ
- Society for Scholarly Publishing in Chicago, June 1-3.
Drop us a line if you’re planning to attend these events and we will be delighted to meet up!
SeamlessAccess is now available in multiple languages
We’re thrilled to announce that SeamlessAccess now supports internationalization. We believe this is an important value-add for the service, given that SeamlessAccess has a very international user base and is all about providing those users with easy, intuitive access journeys. Internationalization features for SeamlessAccess were made available for testing in Beta back in February, and have now been deployed to the main SeamlessAccess service.
At this moment SeamlessAccess is available in two languages: English and Spanish. We hope that, with the help from the wider SeamlessAccess community, many other languages will follow soon. If you are willing to support this effort, please consider contributing to the set of translations via our GitHub repository.
Access Apocalypse: Be Prepared for Anything (NISO+ video)
Several members of the SeamlessAccess team, including Heather Flanagan, Tim Lloyd, and Jason Griffey presented at the NISO Plus 2022 conference in February on the topic of upcoming browser technology changes and their effects on access to resources. That presentation, entitled “Access Apocalypse: Be Prepared for Anything”, is now available in the Seamless Access Learning Center. This session walks through current and evolving changes in access methods to explore how the information community can maintain workflows that minimize access friction for users, deliver an engaging and personalized experience for service providers, and protect data privacy.
STM Trends 2026
The latest STM Trends infographic entitled “The Beauty of Open at Scale” is now available. Based on discussions with dozens of experts, the STM Trends series have proven to be an engaging and informative way to identify technology-driven trends that are likely to impact the scholarly communications ecosystem in the next three to five years - which helps set the scene for how services like SeamlessAccess can continue to add value in the future.
Introduction to the graphic and a lively panel discussion around its themes took place on Tuesday, April 26, 2022, with a recording available here. Speakers took a deep dive into lessons from OA publishing; Diversity, Equity, Inclusion, and Accessibility; author engagement; metadata and discoverability; and more.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Maintenance April 19
Note: updated date! SeamlessAccess has scheduled maintenance on:
April 19, 2022 8:00AM - 12:00PM UTC
We have booked a four-hour maintenance window to upgrade SeamlessAccess to version 1.6.2. We expect that end-users will not experience any interruptions during this maintenance window, however it is possible that there may be some caching issues.
Please refer to the SeamlessAccess status page for more details: https://status.seamlessaccess.org/
Update: Maintenance was succesfully completed
Maintenance
SeamlessAccess has planned maintenance on:
March 29, 2022 8:00AM - 12:00PM UTC
We have booked a four-hour maintenance window to move the front-end service from GitHub Pages to a new infrastructure. The team will try to make sure that end-users won’t experience any issues during the maintenance, however it is possible that, at moments during this time window, the service is temporarily unavailable.
Please refer to the SeamlessAccess status page for more details: https://status.seamlessaccess.org/
Update: Maintenance was succesfully completed
Model License Agreement Call for Comments
We are pleased to announce the second output from the Contract Language Working Group, whose job it is to build on the Entity Category work to produce a toolkit for use in contracts between libraries and service providers (and for service providers to have as a reference for library requirements). This group is working to develop a toolkit that can be used to update contracts and documentation to help libraries and providers choose the appropriate entity category for the resource and outcomes they desire. The first document from the toolkit was the Entity Category Use Case Scenarios released last year.
Today, the Contract Language Working Group is happy to release its Model License Agreement with Commentary document for comments. The Model License is presented in the form of a contract, with sections specific to Federated Authentication issues and commentary from the authors highlighted with purple text for ease of identification.
From the introduction to the document:
This Model License Agreement (“MLA”) has been prepared to assist information professionals, executives, and others who offer or acquire digital content in a library or similar setting. The intent of this MLA is to present a sound and realistic template of the key issues involved in negotiating a license to acquire or use digital content, specifically as it relates to the world of Federated Authentication & Authorization.
Comments may be left directly on the Google Doc until March 31. We will be revising the document as we move forward in our work and towards the release of the 1.0 version of the Model License as well as the full Contract Language Toolkit. We look forward to your feedback.
Events
With travel and conferences resuming, here are some opportunities to meet us in person:
- Council of Science Editors meeting, May 1-3 in Phoenix, AZ
- Society for Scholarly Publishing, June 1-3 in Chicago.
Drop a line if you’re planning to attend these events. We would be delighted to meet up!
ALA committee on Federated Authentication
Core, a division of the American Library Association, has created a new Federated Authentication Committee that will focus the library community’s efforts in understanding, evaluating, and implementing federated authentication as an access mechanism for library resources. Part of the responsibilities of this committee will be to assign a member to be a liaison to the SeamlessAccess governance committee and be a voice for the library community in the broader federated authentication conversation.
We at SeamlessAccess are very excited about having additional library voices as a part of our work.
SeamlessAccess 1.6.2 in Beta
Back in the fall of last year, we called on your help for translations to make SeamlessAccess available in multiple languages - something that we feel is very important given our focus on usability and the diverse, international user base that we serve. Translations are still very welcome if you’d like to contribute to the project in this way (for instructions on how to do that, see our October newsletter).
We’re delighted to announce now that SeamlessAccess 1.6.2, including internationalization, is available in Beta. We kindly ask you to test the release at https://use.thiss.io/, and let us know if you encounter any problems or issues via GitHub.
For more detail, please see the release notes.
Wolters Kluwer and Mark Allen Group implement SeamlessAccess
We’re thrilled to announce that two more publishers have integrated with SeamlessAccess this month.
Wolters Kluwer have integrated SeamlessAccess on their OVID platform, giving a prominent place to the SeamlessAccess button in the top-right of the article landing page. “Wolters Kluwer is excited to now provide our customers with the opportunity for a simplified login experience through SeamlessAccess. Starting on March 1 we’ve made authentication and access easier for our Ovid journals experience users as a pilot for the WK organization. We look forward to implementing SeamlessAccess within other products in the future.”, says Nicole Caputo, Senior Product Manager, Ovid.
Mark Allen group, a family-owned, independent media communication company, have completed an advanced integration with the support of their platform host Atypon. “Mark Allen is delighted to have integrated SeamlessAccess into our MAG Online Library site. Ease of access is vital for our diverse audiences, so enabling SeamlessAccess on the site promises to be a significant step forward.”, says Tom Pollard, Product Director, Digital Resources at Mark Allen Group.
We are delighted to have these organizations on board and expect other publishers to join soon!
For a list of (known) SeamlessAccess integrators, please see https://seamlessaccess.org/stakeholders/for-service-providers/.
Welcome Inge Schoutsen
At the end of January we announced that SeamlessAccess was looking for a lead UX designer. We’re very happy to let you know in this newsletter that we have found that person! Inge Schoutsen has joined the team to carry on this important work for SeamlessAccess. She will be focusing on providing design guidance and help SeamlessAccess deliver a streamlined access experience for researchers around the globe as well as plan and help execute ongoing validation of existing and evolving design recommendations. She will also work closely with the development team and our stakeholders from multiple organizations.
Inge is an allround UX/Product Designer & Strategist with 20+ years of experience working at digital design agencies, tech companies and scholarly publishers. Next to her design practice, she is an artist represented by Josilda da Conceição gallery in Amsterdam, where she is based.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Events
SeamlessAccess was included in two webinars back in December:
- 8 Dec: STM Solutions Seminar, featuring a presentation by Matthew Keen (IOP Publishing) on SeamlessAccess
- 14 Dec: Atypon webinar, featuring Heather Staines talking about SeamlessAccess (amongst other topics)
Looking ahead, the SeamlessAccess team is planning a new integrator workshop as well as continuing our series of SeamlessAccess for scholarly publishers - stay tuned!
REFEDS Entity Categories
The REFEDS community is currently working through existing Entity Categories, two of which having been originally proposed by the SeamlessAccess Entity Category Working Group, to bring them up to the necessary precision for this type of specification. These specifications must be very specific and targeted in scope, describing exactly what data attributes are to be released when these Entity Categories are used. The question of how and when a service provider should use these attributes, however, is out of scope for a specification.
Entity Categories are important because they make the process of attribute release much easier to manage. They help match the data and privacy requirements of the Identity Provider with the requirements of the service itself. They also allow administrators of identity management systems to have easy-to-use configuration guidance that supports appropriate information sharing between parties. Entity Categories also offer business units within the institution the opportunity to refer to these descriptions in their contractual language with Service Providers.
All changes ultimately must be approved by the community. If you would like to stay abreast of public consultation announcements for these and other REFEDS specifications, please join the REFEDS consultation mailing list.
Approach towards refreshing local browser storage
We are happy to announce that, with the next release, SeamlessAccess’ central discovery service will start to refresh information kept in the user’s browser local store.
SeamlessAccess is all about making the login experience as intuitive, easy, fast and stable as possible. To realize this, SeamlessAccess maintains a searchable database of metadata about Identity Providers (IdP’s), and stores that metadata for often-used IdP’s in the user’s browser local storage. Thanks to this persistence mechanism, SeamlessAccess can display the user’s IdP preferences without having to communicate with a central infrastructure - making the system both robust and fast.
While information about IdP’s does not change very often, changes do occasionally occur and SeamlessAccess has been working on a way to keep this information up to date. Because of the distributed nature of how metadata is stored in each browser, this is actually not a straightforward problem for SeamlessAccess to solve!
The next release will offer a first step towards solving this challenge. In future releases, we will also start to clear out IdP metadata that cannot be refreshed or that has been deleted from the metadata service. We will be working with advanced integrators to plan for this change in order to make sure users are not affected in a negative way.
Welcoming Wendy Shamier
Wendy Shamier has joined the SeamlessAccess team as Business Development Manager this January. She will be focusing on business aspects of SeamlessAccess’ transition from the current beta phase to a fully production-level service, including the development of a sustainability plan and a pricing model. She will also work closely with other SeamlessAccess staff on defining and developing processes for full life-cycle customer engagement.
Wendy has a background in IT consulting, most recently as Service Level Manager and Research IT advisor for SURF, the collaborative organization for information and communication technologies in Dutch education and research. In addition to this she has a decade of experience in academic publishing, working as a Publisher for Brill and Elsevier. Wendy is based in Amsterdam and can be contacted at wendy@stm-solutions.org.
Lead UX designer vacancy
SeamlessAccess is looking for a strategically minded senior UX practitioner to join our team!
Are you interested in taking a lead role to provide design guidance and help SeamlessAccess deliver a streamlined access experience for researchers around the globe? Check out the job description on our vacancies page.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
SeamlessAccess is looking for a Lead UX designer and strategist
Seamless Access is looking for a strategically minded senior UX practitioner to join our team! Are you interested in taking a lead role to provide design guidance and help SeamlessAccess deliver a streamlined access experience for researchers around the globe? Check out the job description on our vacancies page.
Extending the benefits of SeamlessAccess to a new audience
SeamlessAccess hit an important milestone recently with the addition of our most recent service provider, The HistoryMakers.
While over the last years we’ve seen growing traction with global publishers of science, technical and medical content, the benefits of more seamless access are just as relevant and important to the broader community.
The HistoryMakers is a non-profit research and educational institution committed to preserving and making widely accessible the untold personal stories of both well-known and unsung African Americans. SeamlessAccess makes it easier than ever for students, educators and researchers to access The HistoryMakers Digital Archive, an internationally recognized archival collection of thousands of African American video oral histories.
The addition of The HistoryMakers also marks a valuable new use case for SeamlessAccess, with a user’s stored organisational affiliation used to streamline library card authentication in addition to federated authentication. This extends the benefits of SeamlessAccess outside traditional academic communities to a broader range of library users around the world.
“Simplifying access is essential to our mission of making the HistoryMakers Digital Archive accessible to researchers and educators. By removing barriers to access, SeamlessAccess helps us showcase the breadth and depth of the accomplishments of individual African Americans”, said Julieanna Richardson, Founder and President of The HistoryMakers.
About The HistoryMakers
The HistoryMakers is a national 501(c)(3) non-profit research and educational institution committed to preserving and making widely accessible the untold personal stories of both well-known and unsung African Americans. Through the media and a series of user-friendly products, services and events, The HistoryMakers enlightens, entertains and educates the public, helping to refashion a more inclusive record of American history. Learn more at https://www.thehistorymakers.org/.
Events
Here are two past events with recordings that we highly recommend: Heather Flanagan spoke about “Browser Changes and the Impact on Federated Identity” at IAM online on Nov 11. A video recording is available here. Heather Staines gave an overview of both SeamlessAccess and GetFTR as part of the PubFactory Virtual Series 2021 on Oct 15; the recording can be found here.
And there’s more coming up!
- 8 Dec: STM Solutions Seminar will include a contribution on SeamlessAccess
- 14 Dec: Atypon webinar about GetFTR & SeamlessAccess
Internationalization - calling on your help!
Given the international character of research, it is not surprising that many of the digital products that integrate with SeamlessAccess serve a diverse and international user base. Several of these offer internationalization options, giving their users a choice in language that they would like to see and interact with. SeamlessAccess is devoted to providing users with an easy, intuitive access journey - which also means that we want to support the user in their language of choice.
Internationalization has been on our roadmap for some time, and today we are very pleased to announce that we are ready to start supporting other languages - and we are calling on your help to offer SeamlessAccess in your local language. If you are willing to support this effort, you can do that by contributing to the set of translations in our GitHub repository. If the language you would like to contribute to is not available yet, please create a
Extending the benefits of SeamlessAccess
SeamlessAccess is delighted with the recent adoption of the service by The HistoryMakers, a non-profit research and educational institution committed to preserving and making widely accessible the untold personal stories of both well-known and unsung African Americans.This integration is a significant milestone because it exemplifies how SeamlessAccess can provide value to a broad range of library users around the world and in a variety of use cases.
“Simplifying access is essential to our mission of making the HistoryMakers Digital Archive accessible to researchers and educators. By removing barriers to access, SeamlessAccess helps us showcase the breadth and depth of the accomplishments of individual African Americans”, said Julieanna Richardson, Founder and President of The HistoryMakers. Read more about it in our recent blog post.
Understanding Where-Are-You-From (WAYF) Challenges
The WAYF Entry Disambiguation Working Group has written a short white paper describing when and how users might be confused by the IdP Discovery WAYF service. Establishing the challenges in this space is the first step towards determining potential solutions for what will become a larger issue as federated authentication services proliferate.
Updates to Terms of Service
We’re making two minor changes to SeamlessAccess’ terms of service for reasons of transparency. First, we have added a sentence to clause 4.3 to more clearly describe the user experience review process before a new integration is released. This process helps to make sure that researchers will have a clear and consistent user experience when using SeamlessAccess across different applications. In addition, we’ve added “This is subject to change” to clause 6.7 to more clearly indicate that SeamlessAccess retains the freedom to move away from the current model of offering the (Beta) service for free to Service Providers in the future.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Upcoming (and Past) Events
On October 14, Heather Flanagan will be speaking about SeamlessAccess and related topics at “Cyber Security in Higher Education”, sponsored by SNSI. Register here
On 24 September, Heather Staines spoke about SeamlessAccess in the webinar “Identity in Research Infrastructure: An overview of how identity is managed in scholarly infrastructure” during Peer Review Week 2021. A recording of the session is available here.
Emerald integrates with SeamlessAccess
Emerald Publishing has implemented SeamlessAccess on the Emerald Insight platform, making it easier for researchers to seamlessly access research from any place and any device. The implementation was done through an integration with LibLynx’s identity & access solution.
In a joint Press Release, Hylke Koers underlined the network effect that underpins the value SeamlessAccess in delivering to users, and how every new integration strengthens this: “We are delighted that Emerald has integrated the SeamlessAccess service on its Insight platform, helping researchers enjoy easy and safe access to content from any location. SeamlessAccess remembers the user’s institutional choice across different publishers’ websites, which means that publishers who join SeamlessAccess – in addition to receiving direct benefits - also contribute to a broader network effect that improves access experiences for researchers across the scholarly web.”
FAQ on Browser Privacy Changes and Library Resource Access
Earlier this year, we already spoke and wrote about upcoming changes to the way that browsers work that are bound to have a significant impact on how researchers access online resources. This is relevant not only for federated authentication (the mechanism that SeamlessAccess builds upon) but also for IP-based access mechanisms, which are still in wide use today in the research community.
The feedback that we have received tells us that the information we shared was found to be really valuable, but equally that there is a significant gap in knowledge and awareness about these changes. In order to help close this gap, we have put together an FAQ on Browser Privacy Changes and Library Resource Access. While the FAQ is primarily intended for librarians and IT departments, we expect that many others will find it useful as well.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Upcoming Events
On 24 September, Heather Staines will be talking about SeamlessAccess in a webinar entitled “Identity in Research Infrastructure: An overview of how identity is managed in scholarly infrastructure” as part of Peer Review Week 2021. You are cordially invited, please register here.
SeamlessAccess and the User Journey
SeamlessAccess is all about providing a seamless, intuitive user experience, with the ideal being that it “just works” with as little user interaction as possible. Interestingly, that also means that it is not always obvious to users what exactly SeamlessAccess is doing for them, and how their user experiences would be different without it. To explain the value of SeamlessAccess in a visual and easily digestible way, we have created a series of videos that are available on our Learning Center.
The latest video in this series, just released, is called “SeamlessAccess and the User Journey”. It offers a step-by-step description of the access user journey from a researcher point of view, demonstrating how SeamlessAccess is making the whole process of accessing a journal article much more straightforward. Check it out here.
Feedback from Integrator Workshops
Over the summer period, we organised three workshops for SeamlessAccess integrators and federation operators. Collectively, these were attended by close to 100 individuals which meant that we were able to get a lot of valuable feedback from different angles on SeamlessAccess’ current offering and our plans for the future.
By and large, the feedback suggested that we have the right items on our current roadmap. In particular, IdP filtering and internationalization were confirmed as priorities, and the team is actively focusing on these topics at the moment. Additional items that we will be taking on board include branding (especially for federation operators) and thinking through the options to include non federated IdP’s such as social in the central discovery service. We always value further feedback: We have a SeamlessAccess Slack channel for general discussions with our community, and any concrete issue reports or feature requests can be submitted as an issue via GitHub.
Once we’re done implementing internationalization, we will be looking for contributions for translations - stay tuned!
Apple’s iCloud Private Relay impacting IP recognition
Even though SeamlessAccess focuses on Federated Authentication as the best technology to enable researchers to access digital resources in a user-friendly and secure way, we realize that for many organisations and for many use cases IP-recognition is still an important access mechanism. With that in mind, we’d like to raise awareness within our community for ongoing work at Apple (dubbed “iCloud Private Relay”) that will anonymize IP addresses for Safari users on both iOS and MacOS. Very recently, Apple published a document that provides guidance for network administrators to prepare their institutions on how to deal with these changes.
These developments at Apple fit into a larger story as changes in legislation and expectations with regard to user privacy are driving significant changes at browser vendors over the next few years - with potentially huge impact on the scholarly web and services like SeamlessAccess. If you’d like to know more about what’s happening in this space, we highly recommend a recent webinar “Web browsers, privacy, and your publishing platform webinar” by Heather Flanagan.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Upcoming Events
On 15 July 2021, the STM Association will be hosting a free webinar on “Web browsers, privacy, and your publishing platform webinar.” In this session, we’ll discuss the changes browser vendors are making to prevent ad networks from tracking users without notice.
SeamlessAccess and Browser Changes
Above, we mentioned the webinar scheduled for 15 July 2021. The changes on the browser roadmap are particularly important to organizations that support controlled access to online resources. The changes on the roadmap for all browsers, while important for privacy, are also impacting browser features used to support federated authentication and even IP address authorization. SeamlessAccess is watching this space closely and will provide regular updates and recommendations to our community so we can adapt to whatever changes are implemented by the browser vendors.
Read more about this in our recent blog post: Web browsers, privacy, and federated identity
The SeamlessAccess Product Roadmap
Work on SeamlessAccess is an ever-evolving set of activities. Over the next few months, we expect several features to be released, including progressive scrolling on the Standard IdP discovery page and various internationalization improvements. Much of our planning and development work is focused on improving how we signal to a user that a given IdP is more or less likely to work with a given service provider. The roadmap is now available on our website and will be updated regularly.
Staff Change
As of July 1st, Hylke Koers has taken over the baton from Heather Flanagan as SeamlessAccess’ Program Director. Hylke recently joined the STM Association as CIO for it’s new STM Solutions initiative, which has access as one of its priorities. Hylke is excited to be part of SeamlessAccess and looks forward to working with the SeamlessAccess community and helping shape its future direction.
Heather Flanagan will continue to stay involved as Technical Liaison, working on an optimal coordination and collaboration between SeamlessAccess and relevant other community groups as well as contributing to the more technically-focused Working Groups.
Eefke Smit, Director S&T of STM and one of the long-term sponsors of SeamlessAccess, says:
“Heather came as a gift from heaven to the project - a woman with exactly the right expertise, the right network and a well-fitting skill set. She took a key role in developing it from RA21 (Resource Access in the 21st Century) into SeamlessAccess.org. This was now 5 years ago. The rest is history – our gratitude for her contributions live on. Her new role will be equally valuable for the future of the project, with SeamlessAccess now ready to go operational."
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Web browsers, privacy, and federated identity
Dr. Jane Smith is a postdoc at a major research institution. Overnight, she upgraded her Apple Macbook to the latest version of Apple’s MacOS. While in her lab she powers up her Macbook and connects to the campus WiFi network. She reads an email from a colleague containing a link to a recently published journal article. She clicks the link, which launches the Safari browser on her Macbook, but receives a message from the publisher’s website saying she doesn’t have access to the article. Strange. She browses to a journal on another publisher’s website that she reads on a regular basis, and also finds she doesn’t have access. Really strange. She asks a colleague in the lab if he is having trouble accessing journal articles. Access from his Windows laptop is working just fine.
This scenario could begin to happen at campuses across the globe in the not-so-distant future. Browser vendors are beginning to signal changes they plan to make that will bolster privacy but could also cause unintended disruption. On June 7, 2021 during Apple’s WWDC conference, Apple announced that subscribers to their iCloud+ service will have their IP address obfuscated from website operators. This is a strong signal regarding Apple’s thoughts on how to protect privacy, and this kind of feature will almost certainly make its way to the rest of Apple’s products (like Safari). While Apple is making this move (and others) to protect user privacy, for an industry that has leveraged IP address recognition as the predominant means of authorizing access to scholarly resources, the potential for unintended disruption is massive.
Even more recently, Google has recommitted to removing support for third-party cookies in 2023. While that is a delay from their original timeline, again we’re seeing browser vendors move in the direction of supporting consumer privacy, potentially at the expense of other legitimate use cases.
Services like SeamlessAccess and even the underlying federated authentication infrastructure utilize various means of exchanging information across website operators. The significant challenge the browser vendors face is trying to distinguish between legitimate use cases and those that are more suspect. The browser vendors would all likely agree that exchanging information among trusted third parties for the purpose of facilitating access to scientific and scholarly resources is quite different from tracking users’ website visits for the purpose of facilitating targeted advertising. However, both of these situations use the same underlying features.
It’s important to note that some of the potential changes under discussion could disrupt usage patterns in common use today. Over twenty years ago, IT architects and visionaries put together ideas for single sign-on (SSO) services that now span the Internet. They developed the Security Assertion Markup Language (SAML) and began organizing the other various systems components to make SSO function. As mobile devices became more prevalent, the limits of SAML led people to develop OAuth, and from there, OpenID Connect. (If you’ve logged into a website using your Google account, you’ve used OpenID Connect.) And, through all of this innovation and development, the most common medium for users to log in and access services and content was via the World Wide Web.
SSO services that use a third-party’s account information are known as “federated.” An individual’s federated identity is their identity information, hosted at one organization like their school, employer, or favorite social media service. Federated identity is used by various service providers to let a user login without creating a new account. The benefits to this arrangement include fewer passwords for a user to keep track of, improved privacy when the user does not need to offer personal information to create an account, and fewer ways for a hacker to compromise service providers. If the service provider doesn’t store the password, the password can’t be hacked through their systems. Federated authentication also supports an additional benefit of allowing for granular release of information about the user (i.e., this site gets this information about the user, while that site gets different information), which, if used properly, can add to privacy and anonymity of the user.
Several pieces of functionality in web browsers enable the features that support federated single sign-on. One of those features are browser cookies. Cookies come in various types, but what they all have in common is that they put a small bit of data in a user’s web browser. That data can serve many different purposes: it can let a site know whether or not a user is logged in, it can be used to store information that will allow a service to personalize services in some manner, and, most infamously, it can be used to track what sites a user visits as they surf the web. That last part is how digital advertising networks collect (sometimes personal) information about users to deliver targeted ads. From the browser’s perspective, though, one cookie looks just like the next. The browser cannot tell the difference between a cookie that lets a service know the user is authenticated from a cookie that allows an advertiser network to track a user around the web. That’s a problem when cookies come under fire because of their role in user tracking.
As the world becomes more aware of and concerned with the privacy implications of engaging on the web, and as legislation like GDPR come into effect, browser vendors like Google (Chrome), Apple (Safari), and Mozilla (Firefox) are trying to figure out how to protect user privacy (e.g. by preventing hidden tracking, obfuscating IP addresses, etc.) while also supporting legitimate use cases like federated single sign on.. Since the tools used by both are technically the same, this is a tricky problem to solve! SeamlessAccess, which does not use third-party cookies and does not track a user in any way, relies on information written into the browser’s storage to streamline the Identity Provider Discovery step in federated authentication. Services like this will also break as browsers restrict sites to reading only the information they themselves have written into the browser’s local storage.
Some browser vendors have already taken steps to block third-party access to information in the browser’s local storage. Apple’s Safari is at the forefront of blocking hidden tracking. But as a result, Safari and other browsers running on iOS and iPadOS are also platforms where services like Microsoft Teams just won’t work anymore. Mozilla’s Firefox has partly implemented the limits on third-party cookies but is actively looking for ways to do this more efficiently. And Google is actively developing their Privacy Sandbox but has realized that deprecating third-party access without a plan for federated single sign-on is a problem and may even open them up to anti-trust lawsuits. As the different vendors diverge on how they support what has been basic functionality on the web, there is a potential for users to be restricted to services only working with a specific browser vendor and their ecosystem.
Several proposals are being explored as potential ways to preserve federated single sign-on while preventing hidden tracking. Still, for right now, they are all just proposals. No one has a solution at hand, not even (or perhaps especially) not the browser vendors themselves. Since there is no solution ready outside of prototypes, the question of when third-party cookies will go the way of the Flash protocol is still open. A new community group in the W3C is forming to consider this challenge in depth - stay tuned to learn more about what happens from here.
SeamlessAccess is monitoring these developments closely and is seeking to provide a vehicle for our community to engage in these issues, since they will have a big impact on libraries, publishers, and anyone else who uses federated identity on the web.
Entity Category Use Case Scenarios
The SeamlessAccess project has a number of initiatives that are designed to improve the wider world of federated authentication beyond just the SeamlessAccess service. Recognizing that existing solutions weren’t suitable for many of the use cases that libraries and publishers have in today’s information landscape, SeamlessAccess has led a number of efforts to improve the flow of authentication and authorization.
The first of these was the Entity Category working group. Entity categories represent agreements between identity providers (libraries or IT departments) and content providers (publishers or vendors) on the nature of user accessing a service. This working group proposed new Entity Categories for use in the configuration of federated authentication systems that outline which attributes about the user are passed from a subscribing organization to a service provider. These two new Entity Categories (Anonymous and Pseudonymous), which were approved by REFEDS earlier this year, give libraries and service providers the technical specifications needed to manage attribute sharing and protect user privacy. But, as we know, technical solutions aren’t always enough, and we discovered that there was a dearth of useful contract language currently that addresses federated authentication at all, much less specifies these new Entity Categories as the standards for technical implementations.
To help in this area, SeamlessAccess convened the Contract Language Working Group, whose job it is to build on the Entity Category work to produce a toolkit for use in contracts between libraries and service providers (and for service providers to have as a reference for library requirements). This group is working to develop model language that can be used to update contracts and documentation to help libraries and providers choose the appropriate entity category for the resource and outcomes they desire.
Today, the Contract Language Working Group is happy to release its Entity Category Use Case Scenarios document for comments. From the introduction to the document:
The goal of this document is to outline the various use cases in order to determine the overlap between user access, authentication and authorization, attribute release, and entity categories used in the federated authentication communication between the Identity Provider and the Service Provider. These use cases will be used to ground the contract language in real world examples.
Comments may be left directly on the Google Doc, and we will be revising as necessary as we move forward in our work and towards the release of the full Contract Language Toolkit. We look forward to your feedback.
Upcoming Events
If you’re interested in a different perspective on federation, education, and research, GÉANT’s TNC21 conference, June 21-25, is always a great source of information. It is also free and entirely virtual this year. More information is available at https://tnc21.geant.org/.
ALA Annual runs from June 23-29, and always has excellent content for the library community. This year, Jason Griffey (NISO) and John Felts (Coastal Carolina University) are presenting a case study on SeamlessAccess to show how one library has approached the use of federated identity as part of their services.
Sharing the User Experience Research
Best practice guidance from SeamlessAccess comes from research into what users find most useful. We share that guidance with the community in the hopes that others will find it useful as they design their own federated authentication workflows. Most recently, we have completed and published a Click Test Research Report which presents the results of user experience tests across four different sites, focusing on what worked (and what did not) in helping the user through the workflow. See more on our User Research Insights documentation page (scroll down to the Click Test Research report at the bottom).
The SeamlessAccess Product Roadmap
Work on SeamlessAccess is an ever-evolving set of activities. Over the next few months, we expect several features to be released, including progressive scrolling on the Standard IdP discovery page and various internationalization improvements. Much of our planning and development work is focused on improving how we signal to a user that a given IdP is more or less likely to work with a given service provider. Below is a copy of our roadmap, which shares our goals and target dates (though the target dates will likely change as real-world activities impact our efforts). We will keep you informed via the newsletter as new features are released!
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This service is governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries, identity providers, and federation operators. We’re excited to bring you up to date on the latest news.
Welcome, Dr. Hylke Koers, CIO of STM Solutions Dr. Hylke Koers joins STM from a strong background in education, research, and scholarly publishing. He will serve on the SeamlessAccess governance committee as STM’s representative. More information on Dr. Koers and STM Solutions is available on the STM website.
Upcoming Events
On April 27, the STM Association’s Society Day will include a session on SeamlessAccess and GetFTR. The event is free for STM members, and only USD$50 for nonmembers. See more information on the meeting website: https://www.stm-assoc.org/events/stm-spring-conference-society-day-2021/.
If you’re interested in a different perspective on federation, education, and research, GÉANT’s TNC21 conference is always a great source of information. It is also free and entirely virtual this year. More information is available at https://tnc21.geant.org/.
The New REFEDS Entity Categories
Last year, the SeamlessAccess working group on Entity Categories and Attribute Bundles sent a proposal to REFEDS for three new entity categories: Authorization Only, Anonymous Authorization, and Pseudonymous Authorization. The purpose of an entity category is to make a simpler and more standardized way for both Service Providers and Identity Providers to request and share a very specific set of information about a user. While the Authorization Only category was not approved by REFEDS as conflating authentication (the ability to log in) with authorization (the access control information) is poor security practice, Anonymous Authorization and Pseudonymous Authorization were approved unanimously by the REFEDS Steering Committee after the community consultation. A blog post on the approved entity categories is available on the REFEDS blog. See https://refeds.org/a/2558.
Identity Provider Filtering in SeamlessAccess
Thoughts on architecture
By Leif Johansson, Head of Infrastructure Services for SUNET and architect for SeamlessAccess
Today SeamlessAccess presents a single view of all the identity providers it knows about - a single set of IdPs is available for searches to whatever SP is calling the discovery service.
This presents a problem because of the reciprocity problem inherent in how identity federations based on SAML federations work. In this blog post, we will describe the problem and how we propose to solve it.
The reciprocity problem means that Identity federations where technical trust is based on public-key signatures of shared configuration information (aka metadata), while highly scalable, suffer from a basic asymmetry of technical trust: An IdP can choose to trust an SP without any guarantee or even knowledge that the SP will reciprocate and trust the IdP. This causes a fundamental usability problem; A user may be offered an IdP as a possible login choice that will recognize the SP.
In enterprise deployments, this doesn’t happen because establishing trust between SPs and IdPs is always a manual process that is guaranteed to be reciprocated. This approach does not scale however which is why larger federations for decades have been willing to accept a certain amount of pain resulting from the lack of reciprocity of trust inherent in relying on signed metadata to scale federations.
The obvious solution is to always present the user only with such IdPs, that SP made its service available to. In the classical single-federation case (ie when there are no interfederations in place) this is still pretty easy because the federation operator will typically deploy a discovery service configured using the shared SAML metadata of both IdPs and SPs.
With interfederations in play, things become a lot more complicated; an SP may or may not be present in a particular interfederation. This information needs to affect the subset of IdPs available to the discovery service.
A case that is recently affecting many users of SeamlessAccess is that OpenAthens is part of the set of metadata trusted by SeamlessAccess. Some SPs using SeamlessAccess trust OpenAthens (e.g., publishers) and some do not. Because SeamlessAccess can’t tell the difference between these two types of SPs, it will present OpenAthens IdPs even to the users of SPs that do not trust OpenAthens. The result is a very confusing user experience.
Since SeamlessAccess will continue to serve multiple federations we need to be able to present a set of Identity Providers tailored to each SP. A commonly used term of art for the ability to present a tailored set of IdPs to users of a particular SP is to filter the set of IdPs. Filtering implies SP presenting a set of parameters to the SeamlessAccess discovery service that is used to tailor the user experience when presenting IdPs.
There are three basic problems we have to solve when designing filtering for SeamlessAccess:
What parameters/capabilities are needed to express the common use-cases? How are filtering parameters communicated to the discovery service? How is filtering signaled to the user?
The user interface is (unsurprisingly) the hardest problem. Usability is a core value for SeamlessAccess and our UX team is working on methods for signaling filtering with the user through UX elements. The major issue is that the trust profile of an SP is often at odds with the expectations of the user. Let’s look at an example to illustrate this:
Kenny from Podunk University typically uses the Podunk University IdP for accessing all his services. As a result, all of Kenny’s browsers have the PU IdP in browser local storage for SeamlessAccess and when visiting SPs, Kenny’s browser always presents his default choice of IdP.
All is well.
Unfortunately, PU has not yet implemented MFA (multifactor authentication) and one day Kenny is invited to authenticate to a service that requires MFA. The service is using the new filtering capabilities to signal that only IdPs that are capable of MFA, and are tagged as such in metadata, should be presented to the user.
The UX challenge, in this case, is this: what should be presented to Kenny? Should the button be empty (appear as non-configured) because the IdP does not belong to the set of permitted IdPs for the SP? Or should it present the next working IdP choice from users’ browser local storage? How should the discovery service behave when Kenny nevertheless tries to search for “Podunk University”. Remember that Kenny may not even be aware that the SP in question requires MFA and may be quite surprised (irked even) when Podunk University fails to appear as expected in search results.
The objective of this exercise is to get Kenny to a fallback IdP that supports MFA, or in the worst case to inform Kenny that he won’t be able to authenticate to the SP at all. The thing we want to avoid at all costs is sending Kenny on a frustrating wild goose chase through various helpdesks only to find out that he won’t be able to login that day. We want Kenny to succeed or to fail quickly - and hopefully to understand why.
The choice of filtering parameters is the subject of an ongoing dialog within the SeamlessAccess community. We are relying heavily on feedback from federation operators, publishers, and research infrastructure providers (e.g., in the AEGIS community). The basic set of parameters seems to include selecting based on (combinations of):
- federation membership
- explicit listing of IdPs
- capability of the IdP (e.g., by entity attributes)
- source of the federation
Finally providing filtering parameters to the discovery service can be done in basically two ways:
- via the front-channel, by providing filtering parameters in the discovery service protocol request. This is best represented by a proposal from the AEGIS group.
- via the backchannel, by providing filtering parameters as configuration to the discovery service on a per-SP basis.
Modern web architecture would suggest (1) as an obvious choice - developers typically have no problem calling web-based APIs, especially those that are based on HTTP redirects.
However most SAML (and OpenID Connect (OIDC)) stacks are hidden from developers and the discovery process is typically not initiated by the application but by the SAML/OIDC stack which is separated from the application and sometimes even running as a separate infrastructure component on a different VM/kernel than the application itself - e.g., part of a TLS concentrator or frontend cluster.
In the case of commonly used software like Shibboleth, AzureAD, ADFS, SimpleSAMLPHP, or pySAML2 the discovery service is called from deep into the library code; adding parameters for doing filtering is difficult at best and impossible in many situations.
Option (1) is really only fully available to federation proxies where the discovery process is fully under the developer’s control. This represents a relatively small number of deployments and would leave the majority of SPs without a mechanism for filtering IdPs.
On closer scrutiny, other problems with option (1) are revealed: Sending parameters in the front-channel will affect the cache-friendly property of the current application which could have a pretty severe impact on SeamlessAccess scalability and the SeamlessAccess application could probably no longer be delivered entirely as an SPA.
There are related proposals (e.g., from AEGIS) covering issues related to proxies that rely on sending additional parameters via the front-channel that are relatively easy for SeamlessAccess to implement and are strongly being considered for inclusion in the SeamlessAccess filtering roadmap. These proposals are not affected by this argument. We will come back to those and other future directions for SeamlessAccess in other posts.
Filtering via the backchannel - option (2) above - means finding some way of conveying filtering parameters for an SP to SeamlessAccess independent of the discovery service request.
Fortunately, there is already a mechanism for providing such configuration information about SPs: SAML metadata. The solution SeamlessAccess is working on currently is to extend SAML metadata with information about which sets of IdPs are trusted by an SP. We are currently working on a specification we hope to present to the SeamlessAccess community and relevant standards bodies for consideration and in parallel, we are working on an implementation.
A downside of using SAML metadata is that it often takes a long time for SAML metadata extensions to be available in the tooling used by federation operators and that it increases the size of metadata. Our plan is to reduce this pain by providing a mechanism whereby SPs can annotate metadata at SeamlessAccess site (aka, “pixie dusting”).
Our roadmap for filtering looks something like this:
- Communicate and get feedback from the SeamlessAccess stakeholders on filtering parameters and UX/UI
- Specify a metadata extension for representing reciprocal trust information that can be used by early adopters
- Identify and implement a possible extension to MDQ that are needed to effectively communicate filtering to the SeamlessAccess frontend
- Implement the chosen UX/UI solution for filtering
- Begin roll-out
- Provide a pixie-dusting service
As soon as we have deployed a mechanism for filtering, we plan to open SeamlessAccess to subscribe to arbitrary metadata feeds - this could be your federation feed (including entities not provided to edugain) or a set of private metadata that is only relevant to a single SP. If it is possible for SeamlessAccess to fetch and update metadata we will make every effort to do so.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. We’re back from a short hiatus in newsletter writing, and the last few months have seen quite a bit of work happening within SeamlessAccess and in the broader federated identity community! We’re excited to bring you up to date on the latest news.
Upcoming Events
On 16 March, OpenAthens is hosting a session at their Access Lab 2021 event that includes a case study on one library’s experience with SeamlessAccess, Shibboleth, and OpenAthens. Registration is now closed, but the content will be publicly available from 1 July 2021. More information is available on the Access Lab page: https://openathens.org/access-lab-2021/.
On April 27, the STM Association’s Society Day will include a session on SeamlessAccess and GetFTR. See more information on the meeting website: https://www.stm-assoc.org/events/stm-spring-conference-society-day-2021/.
If you are interested in learning more about federations around the world, REFEDS will be hosting a free webinar on 1 April that examines the results of the most recent REFEDS Annual Survey. It’s an excellent opportunity to see how different federations are structured, their priorities, and their challenges. Registration is available here: https://events.geant.org/event/581/.
NISO Plus Roundup
The SeamlessAccess session at NISO Plus was a fun and engaging session! Discussion, particularly in the Q&A after the event, was active, with librarians, federation operators, and publishers all involved in better understanding the technologies behind SeamlessAccess. If you missed the session, you can see the recording here: https://nisoplus2021.cadmore.media/Title/dcddde5b-cef9-45dd-a932-cd546c84760b.
New REFEDS Consultation - eduPerson Analytics ID The REFEDS Schema Editorial Board’s subcommittee, the eduPerson Analytics Code subcommittee, has proposed a new attribute to be added to the eduPerson schema – a common schema for identity metadata used globally by education and research organizations – that would provide a way for an institution to send through a set of reporting codes as part of the authentication transaction that a Service Provider could then use to create segmented usage reports. The primary use case captures the need of a publisher/library scenario where data is needed to understand the use of a given resource and be able to classify that resource into buckets (such as internal billing codes). This happens outside the authentication/authorization transaction and so is not itself an entitlement. If you would like to know more about this proposed attribute and the type of information that it would contain, please see the REFEDS Consultation page: https://wiki.refeds.org/display/CON/Consultation%3A+eduPersonAnalyticsID.
This consultation is open from: 4 March 2021 15:00 CET to 5 April 2021 17:00 CET.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. We’re back from a short hiatus in newsletter writing, and the last few months have seen quite a bit of work happening within SeamlessAccess and in the broader federated identity community! We’re excited to bring you up to date on the latest news.
Upcoming Events
Upcoming Events The NISO Plus conference is happening this week, February 22-25, and SeamlessAccess is on the agenda! Come join us on Monday, February 24 for an Introduction to SeamlessAccess as well as a more in-depth conversation, SeamlessAccess - a Conversation between Service Providers and Librarians. Registration is available here: https://niso.plus/register-for-niso-plus-2021/
And on March 27, the STM Association’s Society Day will include a session on SeamlessAccess and GetFTR. See more information on the meeting website: https://www.stm-assoc.org/events/stm-spring-conference-society-day-2021/
Call for Participation: WAYF Entry Disambiguation Working Group
SeamlessAccess focuses on the Where-Are-You-From (WAYF) aspect of the Federated Identity Management (FIM) workflow. The metadata that sources the list of Identity Providers (IdPs) to users is often aggregated from several sources in order to get the broadest list possible. While providing the user as much choice in IdPs as possible is usually a good thing, we are seeing significant confusion when an institution has two IdPs with the same Display Name. Most commonly to date, this is found when an institution has a campus IdP and a library-specific IdP service (although this issue could arise with any organization where multiple IdPs might be implemented).
For example:
From the user’s perspective, these are the same. From a technical perspective, however, these are different. One point to ‘https://login.bc.edu/idp/shibboleth' and the other points to ‘https://idp.bc.edu/openathens'. We are beginning to see this area of potential confusion more frequently, and the above example is just the first that we identified.
This problem touches on every stakeholder in the FIM workflow, from the end users, the librarians, the service providers, the identity providers, and the federations. SeamlessAccess is in a good position to bridge all these groups, and to that end we are forming a new working group to specifically look at this problem and come up with some best practice guidelines. If you are interested in participating, please reach out to contact@seamlessaccess.org to get involved!
#Monitoring the Services The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. We’re back from a short hiatus in newsletter writing, and the last few months have seen quite a bit of work happening within SeamlessAccess and in the broader federated identity community! We’re excited to bring you up to date on the latest news.
Upcoming Events
The NISO Plus conference will be a wholly online event this year from February 22-25, and SeamlessAccess is on the agenda! Come join us on Monday, February 24 for an Introduction to SeamlessAccess as well as a more in-depth conversation, SeamlessAccess - a Conversation between Service Providers and Librarians. Registration is available here: https://niso.plus/register-for-niso-plus-2021/
LIBER’s Federated Identity Management for Libraries
LIBER (Ligue des Bibliothèques Européennes de Recherche – Association of European Research Libraries) is the voice of Europe’s research library community, and hosts the Federated Identity Management for Libraries (FIM4L) working group. FIM4L released their first set of recommendations, “Federated Access to Online Resources: Principles & Recommendations for Library Services.” From the abstract:
“Publishers and suppliers of licensed online resources want to provide authorized users of institutions for higher education and research with access to their services in a controlled way. This document aims to function as a reference for libraries and publishers who want to set up an SSO connection.”
Please feel free to join the conversation. More information about FIM4L is available here: https://www.fim4l.org
Kicking off the First Integrator’s Workshop
Service Providers who have a SeamlessAccess integration in production met in December to discuss various aspects of the user experience, share best practices, and discuss the SeamlessAccess project road map. The group focused on evolving aspects of the user experience, among them, the varied approaches implementers have taken for displaying when there is an IdP choice stored in the browser but that institution either is not configured for federated access or does not provide access to the content or service. The participants also reviewed user experience recommendations for notifying the user about what is being saved in their browser and what entity is doing the saving.
These discussions were exploratory in nature; the goal is to work together to refine the best practices based on the real-world experience these implementers bring to the table. Our goal is to have these meetings once a quarter. Any changes will ultimately be reflected in our documentation and in the implementations themselves.
Lead UX Designer - job posting
And speaking of integrations and user experience, we have posted a contract position on our website for a Lead UX Designer. Please share in your networks! https://seamlessaccess.org/posts/2020-12-31-lead-ux-designer/
An Update on the Proposed Entity Categories As is common with these kinds of diligent standardization processes, it has taken some time, but the final step for approval of the proposed entity categories is expected this month as the REFEDS Steering Committee votes on whether REFEDS will accept the entity categories as revised through the consultation process.
See our blog post, https://seamlessaccess.org/posts/2020-07-08-entitycategories/, for more information on the entity categories and the consultation process.
Contract Language Working Group - Update
The Contract Language working group is working together to put together language that libraries, Identity providers, and Service providers can use to ease the burden of agreeing on contract terms in the face of new federated authentication efforts. Traditional contracts in use by libraries and publishers have focused on IP authentication, and the language needed to allow for federated authentication is very different. Our goal is to produce a toolkit that different players in the authentication efforts can use to have some standard understanding and language to use as federated authentication becomes more and more prevalent in the information ecosystem.
To this end we have thus far agreed on a set of use cases that fit library and publisher needs in regards to information exchange, limiting information exchanged to the minimum necessary for the service in question by using the work of the Entity Category standards mentioned above. The next stage of our work is the development of the toolkit itself, which will take place through at least summer of 2021. .
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
Lead UX Designer & Strategist (part time)
SeamlessAccessLead UX Designer & Strategist – estimated .25 FTE for 6-12 months; Location: remote
SeamlessAccess seeks a strategically minded senior UX practitioner familiar with UX research and design activities to continue the evolution and adoption of SeamlessAccess services among a range of groups and organizations that support the research and education community. SeamlessAccess is actively collaborating with service providers who are implementing the service’s persistence service and/or central identity provider discovery service in a Beta Phase. The UX designer is expected to take a lead role providing design guidance and consulting with the UX teams of implementing organizations, as well as plan and help execute ongoing validation of existing and evolving design recommendations, including usability testing, user research, and analytics.
Success in this role will require close collaboration with the small development team and a diverse set of stakeholders from multiple organizations.
Main tasks:
- Advocate and articulate the SeamlessAccess design principles, patterns, and recommendations to product teams at implementing organizations.
- Understand implementers’ use cases and design constraints and make appropriate design recommendations that will work across a broad-spectrum of implementation use-cases.
- Facilitate workshops, design reviews, and other collaborative working experiences.
- Define appropriate methods to validate the value and usability of design solutions.
- Serve as the advocate for the end user by performing user research, conducting user task analysis, developing use cases, and communicating user needs to stakeholders.
- Update and maintain UX guidelines documentation (see Seamlessaccess.org/documentation).
- Participate in regular design reviews: provide, and engage with, constructive feedback.
- Effectively convey design elements and interactions to the development team, including mobile first visual design and CSS specifications as needed.
- Ensure solution meets accessibility standards.
- Design and help implement aspects of the branding, information site, and other collateral for the service.
Skills and experience:
- Eight or more years of industry experience in UX design, interaction design, information architecture, UX strategy, user research, or similar field.
- Strong portfolio of work demonstrating experience applying user centered design, user analysis techniques, and responsive web design. Experience creating and applying design patterns a plus.
- Demonstrated experience leading complex projects with multiple stakeholders.
- Able to produce design artifacts with tools such as Adobe XD, Sketch, Photoshop, etc.
- Experience designing to meet WCAG 2.1 accessibility standards; ability to interpret and validate that a product meets global accessibility standards.
- Able to take complex information and communicate it clearly, concisely, and accurately.
- Excellent presentation skills.
- Ideal candidate has experience in technologies relating to scholarly communications or publishing. Experience with or understanding of authentication and identity management technologies a plus.
- Fluent in English.
Employment conditions:
This position will be subject to a temporary consultancy contract with the International Association of STM Publishers (STM) against a fixed or not-to-exceed fee and will not entail an employment contract. The first contract will be for 6 months at 0.25 FTE, open to further extensions and possibly at a different work-factor as the project requires.
About SeamlessAccess:
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
To apply:
To apply, please email your resume and a cover letter highlighting your relevant skills and experience and how it applies to the role and requirements outlined, to (contact@seamlessaccess.org).
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. The last two months had quite a bit of work happening behind the scenes, and we’re excited about bringing you up to date on the latest activities within SeamlessAccess.
Welcome, Wiley Online Library
Wiley Online Library, through their platform provider Atypon, is the newest implementer of SeamlessAccess. You can see their implementation by clicking on “Read the full text” for any article.
For the full list of advanced and standard implementers, see our Service Provider page.
SeamlessAccess Code Updates
Over the last few weeks, SeamlessAccess has improved our core search function to support internationalized searches. Also the most recent release for the Identity Provider (IdP) Discovery Service includes a checkbox that allows users to choose not to have SeamlessAccess store their selected IdP in their web browser.
Webinar Links
The International Association of STM Publishers offered a webinar on SeamlessAccess and GetFTR: slides are available at https://www.stm-assoc.org/events/implementing-seamless-access-and-getftr-a-free-webinar-from-stm-and-atypon/ and the recording can be found here; the passcode is: W1Nm*1cA The Springer Nature Summit, “The State of SeamlessAccess,” included a keynote by Jason Griffey (NISO) as well as a panel discussion with Laird Barrett (SpringerNature), Lisa Janicke Hinchliffe (University of Illinois - Urbana Champaign), Linda Van Keuren (Georgetown University Medical Center), and Heather Flanagan (SeamlessAccess). The recording is available online (free registration required): https://register.gotowebinar.com/recording/1844935841431907341?sap-outbound-id=1019B1E80F53147016374421B51AA68614D665F7
Status - Entity Categories
The work to establish new entity categories, initially proposed by the SeamlessAccess Entity Categories and Attribute Bundles Working Group, is currently in review by the REFEDS Schema Editorial Board, maintainers of federation-level entity categories.
What is an entity category?
“Entity Categories group federation entities that share common criteria. The intent is that all entities in a given entity category are obliged to conform to the characteristics set out in the definition of that category.
While Entity Categories have multiple potential uses, they were initially conceived as a way to facilitate IdP decisions to release a defined set of attributes to SPs without the need for detailed local review for each SP. The decision by the IdP would instead be based on the criteria detailed in each SP entity category specification. Categories were also conceived for IdPs to indicate support for the SP categories; SPs would use this information to tailor discovery and other aspects of the user experience.” - REFEDS Entity Categories home page
More information on the proposed entity categories can be found on our blog post: https://seamlessaccess.org/posts/2020-07-08-entitycategories/
#Community Engagement The Contract Language Working Group is continuing its efforts to define and promote language that may be used in contracts that include provisions for Federated Access. While the group is working through existing examples, finding those examples has proven challenging. There is a great deal of improvement to be offered in this space! The working group expects its work will continue through the end of the year, with a public report to be developed in Q1 2021.
#Monitoring the Services The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. The last two months had quite a bit of work happening behind the scenes, and we’re excited about bringing you up to date on the latest activities within SeamlessAccess.
Welcome, ScienceDirect
Since our last newsletter, Elsevier has implemented SeamlessAccess in its ScienceDirect journal. See our announcement: https://seamlessaccess.org/posts/2020-07-28-sciencedirect/
SeamlessAccess v1.3 - New Features!
On 8 September, SeamlessAccess rolled out a new feature for the Identity Provider (IdP) discovery service that supports a user’s choice for allowing SeamlessAccess to store their choice of IdP in their browser. This feature is available by default in the Standard and Limited integrations, and must be implemented directly by the Service Provider (SP) for the Advanced integration.
Upcoming Webinar
Two industry initiatives focused on improving access to scholarly information, SeamlessAccess and GetFTR, have made much progress this year, seeing uptake from major publishers and platforms and growing usage.
Providing streamlined, easy-to-use access to remote users is now even more important due to the global pandemic.
Come hear about the latest developments from both initiatives. Atypon has recently released support for both initiatives on their platform and will be discussing their experience with the projects, as well as providing practical advice on how to activate these features if you use their platform.
Registration is free: https://www.eventbrite.com/e/implementing-seamless-access-and-getftr-a-free-webinar-from-stm-tickets-118367102189
Consultation Period - Entity Categories
The consultation period for the three proposed entity categories closed on 31 August 2020. Originally announced on 6 July 2020, the consultation process included several webinars geared towards a variety of stakeholder groups. A recording of the NISO webinar, geared towards librarians and publishers, is available on the NISO website: https://www.niso.org/events/2020/08/seamless-access-presents-entity-categories-and-attribute-bundles
The next step for these entity categories falls to REFEDS, the home for entity categories like these. The REFEDS Schema Editorial Board will consider the comments received and determine what, if any, any revisions and approvals are required.
More information on the proposed entity categories can be found on our blog post: https://seamlessaccess.org/posts/2020-07-08-entitycategories/
Community Engagement
The Contract Language Working Group kicked off in August with twenty participants from around the world and across different sectors. The goal of this group is to define and promote language that may be used in contracts that include provisions for Federated Access. Outputs from this group will be shared publicly. Stay tuned for more information!
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
ScienceDirect integrates SeamlessAccess to provide improved remote access options for researchers
We are happy to announce that ScienceDirect, Elsevier’s large platform of peer-reviewed scholarly literature, is the latest service provider to go live with SeamlessAccess.
Researchers will now see the SeamlessAccess ‘Access through your institution’ button clearly marked on ScienceDirect article pages. When they click on the button, if their institution has an authorized subscription to ScienceDirect, they are authenticated by their institution and can use ScienceDirect services in the usual way. Elsevier expects that this will provide researchers with more convenient and secure institutional access to its site, anytime, anywhere, and on any device.
ScienceDirect joins the increasing number of services which have implemented SeamlessAccess. By providing a consistent user experience via the SeamlessAccess button across multiple services, we hope to increase user understanding and smooth access to the critical information resources researchers need at a time when their work is more important than ever.
“The impact of coronavirus means the ability to easily work from home is now more important than ever for researchers around the world. The integration of SeamlessAccess on ScienceDirect provides a way for researchers to be able to do this effortlessly on our platform, safe in the knowledge that they are doing this securely, and that their privacy and data is protected. ScienceDirect is the biggest integrator of SeamlessAccess so far, and we look forward to having more publishers and electronic resource owners integrate the service so that we can collectively improve the access experience to many more resources for the research community,” said Gaby Appleton, Managing Director Researcher Products, Elsevier.
More information can be found on Elsevier’s website.
Outreach Survey
A report on the results of the recent surveys of academic IT and library staff to better understand the issues around the implementation of federated authentication is now available: https://seamlessaccess.org/posts/2020-06-23-surveyresults/.
ORCID
SeamlessAccess recently announced the extension of its beta phase at least through the end of this calendar year. ORCID, one of the founding partners of the SeamlessAccess coalition, is currently focusing its efforts on improving core services and adding value to its stakeholders whilst it is in the process of seeking a new Executive Director to lead the next stage of the organization’s development. As a result, ORCID has decided not to participate in the SeamlessAccess coalition during the extension. The other founding partners, GÉANT, Internet2, NISO, and STM have renewed their commitment and continue to support and extend the service during the beta period. ORCID wishes SeamlessAccess continued success and will be following the results of the beta with interest.
Consultation Period
The Entity Categories and Attribute Bundles Working Group has concluded its work and submitted its proposed specifications to REFEDS. These specifications exist to provide common language for Identity Providers and Service Providers to use when describing exactly what information should be released (if any) to enable access to online materials.
A blog post is available that offers links to the consultation process and the registration page for a NISO webinar on August 10, 2020, where we will discuss these entity categories in more detail. See: https://seamlessaccess.org/posts/2020-07-08-entitycategories/
#Community Engagement With the work of the Entity Categories and Attribute Bundles Working Group now in the hands of the broader community, it is time to spin up a new working group that defines and promotes language that may be used in subscriber contracts with provisions for federated access. Contact Jason Griffey for more information!
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between four organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
In order to encourage the clear and consistent operation of federated authentication between Service Providers (such as scholarly publishers), Identity Providers (such as campus IT administrators), and other stakeholder groups (such as librarians), the SeamlessAccess Entity Categories and Attribute Bundles Working Group has proposed three specifications that aim to provide a common set of terms and definitions for use when describing exactly what information should be requested by the Service Provider as well as what should be released (if any) by the institution to enable access to online materials.
These specifications, called Entity Categories, are offered to allow administrators of identity management systems to have easy-to-use configuration guidance that supports appropriate information sharing between parties. These entity categories also offer business units within the institution the opportunity to consider these descriptions as input into their contractual language with Service Providers.
Because these entity categories impact the metadata managed by identity federations, SeamlessAccess has asked REFEDS, the Research and Education Federation community organization, to become the custodians for these entity categories. This includes running the consultation process and managing any subsequent changes to the specifications. NISO will be following this process as well, and will be co-signing these recommended practices as a part of their standards work and work as a member of the SeamlessAccess coalition. All stakeholders in the federated identity management ecosystem are encouraged to offer their comments during this consultation period.
The three entity categories are:
-
Authentication Only - this use case covers authentication only; the Service Provider does not want any attributes (specific pieces of data about an authenticated user) from the Identity Provider, only a confirmation that the authentication was successful.
-
Anonymous Authorization - this use case supports authorization decisions through the sharing of additional information such as entitlement data (e.g., faculty versus student), while keeping the user completely anonymous to Service Providers.
-
Pseudonymous Authorization - this use case supports authentication, authorization, and allows for personalization per Service Provider through the sharing of a per-service user identifier without requesting any personal information such as name or email address.
The public comment period starts on July 6, 2020, and will run for eight weeks until August 31, 2020. Information on how to participate in the consultation is here: https://wiki.refeds.org/display/CON/Consultations+Home. Each entity category has its own consultation page.
NISO will be hosting a webinar on Monday, August 10, 2020, at 10:00 a.m. EDT (14:00 UTC) geared towards librarians and publishers to discuss these entity categories; registration information is available here: http://www.niso.org/events/2020/08/seamless-access-presents-entity-categories-and-attribute-bundles.
The SeamlessAccess Outreach Committee recently conducted surveys of academic IT and library staff to better understand the issues around implementation of federated authentication.
The overall results indicate that there is room for improvement in the communications between academic libraries and their institutional IT departments.
While the surveys were developed to inform our outreach activities, we believe the results will be of interest to the wider community and are sharing our findings. Research questions addressed in the surveys include:
- How many libraries have implemented federated authentication for library resources?
- How well do libraries and IT understand federated authentication?
- How well do libraries and IT communicate about federated authentication?
- How much do libraries and IT know about the NISO RA21 recommendation?
Responses were received from 290 library and IT professionals.
We encourage readers to download our Summary of Findings (9 pages) and explore the results themselves. This document includes information about the survey methodology and response demographics, but comments from survey participants have been excluded to preserve anonymity.
If you have feedback or would like more information about these survey results, please contact SeamlessAccess at contact@SeamlessAccess.org.
We’re excited to announce the publication of the first in a series of videos designed to support learning and education around the SeamlessAccess service.
A key part of our mission is to improve understanding of the technologies that support our SeamlessAccess experience. To date, a significant proportion of our outreach activity has been in-person presentations at meetings and conferences. Given the current circumstances, and our desire to engage audiences that don’t have access to the same opportunities, we are developing a series of educational videos.
The first two video titles focus on addressing questions and concerns about federated authentication, the technology underlying the SeamlessAccess service. Both are designed to provide accessible overviews for a non-technical audience:
-
How Federated Authentication works provides a conceptual understanding of how this technology enables more seamless and privacy-preserving access, including definitions of key terms, such as Service Provider, Identity Provider, and Identity Federation.
-
Privacy, Attributes, and Why They’re Important builds on the previous video to describe the role that Attributes play in preserving user privacy, and the particular challenge that libraries face in configuring library access.
Future videos will address other core topics around the use of the SeamlessAccess service, as well as implementation guides covering the various user communities, such as libraries, technical departments, and publishers.
Over time, we will also expand the range of video features available, including subtitles in multiple languages to improve accessibility.
Our video series can also be found at the SeamlessAccess YouTube Channel.
We welcome your input - please email us at contact@SeamlessAccess.org if you have feedback or suggestions for future videos.
Extension of the Beta Phase
With so many communities learning new ways to function, the governance committee for SeamlessAccess has made the decision to extend the beta period for SeamlessAccess through at least the end of this calendar year. This will allow us to continue to consult with our stakeholder communities on what’s working, and what isn’t, before we announce this as a full production service.
Learning Videos
The SeamlessAccess Outreach Committee has kicked off a video series designed to explain some of the details of federated identity to the world. ‘How Federated Authentication Works’ and ‘Privacy and Attributes’ are available on the new SeamlessAccess YouTube channel, https://www.youtube.com/channel/UCHVM4zXwtO3mKgGxBAwVVaQ. Future videos will include explanations on how SeamlessAccess works, from the user, service provider, and library perspectives, as well as an explanation around the challenges of IP address authorization.
Outreach Survey
Last month, the SeamlessAccess outreach committee sent out a survey to campus libraries and IT support teams to gain a better understanding of the technical environment in which they work. A working group continues to analyze the survey results, and intends to have a report posted on the SeamlessAccess blog by the end of June 2020.
Community Engagement
The Entity Categories and Attribute Bundles Working Group is wrapping up its recommendations for three new entity categories. The goal of these entity categories is to help ease the burden of configuration on the part of the Identity Providers; ultimately, it is the Identity Provider that will decide whether or not to support these entity categories in their systems. The current list is:
- Authentication Only - this use case covers authentication only; the Service Provider does not want any attributes from the Identity Provider
- Anonymous Authorization - this use case supports authorization in addition to authentication while keeping the user completely anonymous to the Service Provider
- Pseudonymous Authorization- this use case supports authentication, authorization, and allows for personalization per SP
All proposed entity categories will go through a public comment process, and will ultimately feed into a new working group that will focus specifically on appropriate contract language to define the terms of attribute release between a library and a publisher. A notice will be sent to this announce list and through social media when the public comment period starts with information on how to review the entity categories.
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between five organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), ORCID, and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This is the monthly update for March 2020 where we catch up on the latest activities within SeamlessAccess.org.
SeamlessAccess in the News
Lisa Janicke Hinchliffe (U. of Illinois at Urbana-Champaign) and Ralph Youngen (American Chemical Society) are the presenters of the next IAM Online webinar on 13 May 2020. Information on federated access and the tools to enable it (including SeamlessAccess!) are the topics of the session. For more information, and a calendar link, see “Simplifying Federated Access to Scholarly Content and Services” on the IAM Online website: https://www.incommon.org/academy/webinars/
And in other news, have you read The Scholarly Kitchen article, “Guest Post – Seamless Remote Access During a Global Pandemic: An Indispensable Necessity”? The article touches on many of the challenges and opportunities to improve access to scholarly content immediately, given the current global pandemic that has closed the physical doors to campuses and research organizations everywhere. SeamlessAccess has played an important role in this for the American Chemical Society; the article is worth a read!
Outreach Survey
Last month, the SeamlessAccess outreach committee sent out a survey to campus libraries and IT support teams to gain a better understanding of the technical environment in which they work. A working group is currently analyzing the survey results, and intends to have a report posted on the SeamlessAccess blog by the end of May 2020.
Community Engagement
The Entity Categories and Attribute Bundles Working Group is almost ready to release its recommendation for three new entity categories. The goal of these entity categories is to help ease the burden of configuration on the part of the Identity Providers; ultimately, it is the Identity Provider that will decide whether or not to support these entity categories in their systems. The current list is:
- Authentication only - this use case covers authentication only; the Service Provider does not want any attributes from the Identity Provider
- Anonymous - this use case supports authorization in addition to authentication while keeping the user completely anonymous to the Service Provider
- Pseudonymous - this use case supports authentication, authorization, and allows for personalization per SP
The group considered whether a fourth category, one that explicitly supported sharing personal information with a particular type of Service Provider, was appropriate. The decision was to not create an entity category for that - any such sharing should be a more explicit, one-on-one discussion between a Service Provider, an Identity Provider, and the user.
All proposed entity categories will go through a public comment process, and will ultimately feed into a new working group that will focus specifically on appropriate contract language to define the terms of attribute release between a library and a publisher.
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can sign up for alerts for outages or to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between five organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), ORCID, and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This is the monthly update for March 2020 where we catch up on the latest activities within SeamlessAccess.org.
SeamlessAccess in the News
Choice, one of the publishing units at the Association of College & Research Libraries (a division of the American Library Association), released a series of podcasts last month on digital access to scholarly content. The podcasts feature interviews with Heather Flanagan, Program Director for SeamlessAccess, and Laird Barrett, Digital Product Manager at Springer Nature. All four episodes are available now at https://www.choice360.org/librarianship/podcast.
SeamlessAccess will be featured on an IAM Online webinar on 13 May 2020. Keep an eye on the IAM Online website for more information: https://www.incommon.org/academy/webinars/
Outreach Survey
Two surveys were administered between February 10-March 27. One survey was aimed at academic IT staff, the other at academic library staff. The purpose of these services is to help SeamlessAccess better understand the diverse situations in academia for accessing online scholarly content. We received 290 responses: 159 from libraries, and 131 from academic IT. Responses were received from 20 different countries, however, the majority were from the US and Europe. More information on the findings from these surveys will be made available on the SeamlessAccess blog later this month.
Community Engagement
The Entity Categories and Attribute Bundles Working Group is currently reviewing proposals for four new entity categories. The names are not final; we’re focusing on the intent for now. The working group will discuss whether it is appropriate to propose all four categories; this list is not final.
- Authentication only - this use case covers authentication only; the Service Provider does not want any attributes from the Identity Provider
- Anonymous - this use case supports authorization in addition to authentication while keeping the user completely anonymous to the Service Provider
- Pseudonymous - this use case supports authentication, authorization, and allows for personalization per SP
- Explicit - this use case supports authorization and personalization by default.
The goal of these entity categories is to help ease the burden of configuration on the part of the Identity Providers; ultimately, it is the Identity Provider that will decide whether or not to support these entity categories in their systems.
All proposed entity categories will go through a public comment process, and will ultimately feed into a new working group that will focus specifically on appropriate contract language to define the terms of attribute release between a library and a publisher.
Monitoring the Services
The availability of the SeamlessAccess services is publicly viewable at https://status.seamlessaccess.org. You can also sign up for alerts to be notified when software updates are made to the services.
SeamlessAccess.org is a service, governed as a coalition between five organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), ORCID, and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This is the monthly update for March 2020 where we catch up on the latest activities within SeamlessAccess.org.
SeamlessAccess in the News
Choice, one of the publishing units at the Association of College & Research Libraries (a division of the American Library Association), is releasing a series of podcasts this month on digital access to scholarly content. The podcasts feature interviews with Heather Flanagan, Program Director for SeamlessAccess, and Laird Barrett, Digital Product Manager at Springer Nature This is a four-episode series, and the first two episodes are available now at https://choice360.org/librarianship/podcast/episode-114 and https://choice360.org/librarianship/podcast/episode-115.
In addition to the podcasts, you may be interested in the collaborative session notes from the NISO Plus session, “Seamless Access — A Conversation between Service Providers and Librarians.” These are community-authored notes from the 90-minute session presented by Ralph Youngen (ACS) and Lisa Hinchliffe (University of Illinois).
If you find these notes interesting, you’ll be even more interested in an upcoming webinar, currently scheduled for May 13. Additional details will be provided in next month’s SeamlessAccess newsletter.
Outreach Survey
The SeamlessAccess Outreach Committee has created a survey to help us better understand how federated identity management is implemented at higher education institutions. The survey is available online and will remain open until 27 March 2020:
https://seamlessaccess.org/posts/2020-02-21-surveys/
#Community Engagement
The Entity Categories and Attribute Bundles Working Group is currently reviewing proposals for three new entity categories:
- Anonymous access - indicating the Service Provider does not want any attributes from the Identity Provider
- Access with pseudonymous identifier/entitlement/affiliation - indicating the information required by the Service Provider to allow for authorization decisions
- Access with personal data/entitlement/affiliation - indicating a request to include personal data
The goal of these entity categories is to help ease the burden of configuration on the part of the Identity Providers; ultimately, it is the Identity Provider that will decide whether or not to support these entity categories in their systems.
All proposed entity categories will go through a public comment process, and will ultimately feed into a new working group that will focus specifically on appropriate contract language to define the terms of attribute release between a library and a publisher.
Stay tuned for more information next month, where we will talk about monitoring services and future webinar opportunities!
SeamlessAccess.org is a service, governed as a coalition between five organizations: GÉANT, Internet2, the National Information Standards Organization (NISO), ORCID, and the International Association of STM Publishers. Participants include researchers, service providers, libraries and identity providers and federation operators, vendors, publishers.
SeamlessAccess intends to improve the way people from universities and colleges around the globe access content and services. To better understand the diverse situation in these institutions we have constructed two short surveys, available till March 27th 2020:
- One for people working in libraries in universities/colleges
- One for people working in IT in universities and colleges
Please either fill out the survey or forward it to mailing lists, websites, or other forums followed by people working in academic libraries or IT.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This is the monthly update for February 2020 where we catch up on the latest activities within SeamlessAccess.org.
Upcoming Conference Sessions
NISO Plus (February 23-25, 2020)
Tim Lloyd (CEO, LibLynx) will offer an introduction to SeamlessAccess for those new to the service, and Ralph Youngen (Director, Publishing Systems Integration, American Chemical Society) and Lisa Hinchliffe (Professor, University of Illinois at Urbana-Champaign) will kick off a more in-depth conversation about SeamlessAccess and its implications in the research and library communities.
Community Engagement
The Entity Category and Attribute Bundle working group, a group of librarians, service providers, and federation operators, continues their efforts to define appropriate mechanisms around attribute release. Attributes are the information that an identity provider such as a library or research laboratory may share with a service provider, and can include signaling when no attributes at all should be released, when specific attributes should be optional, or when specific attributes are required. The group is currently working through various use cases to determine what makes sense and where the commonalities are when it comes to what attributes are required, and when. So far, the use cases suggest the need for two new categories:
-
An entity category to signal a common set of attributes when required by an SP.
-
A no-attribute tag, indicating no attributes at all should be released.
After this working group produces its recommendations, a new group that focuses on how to incorporate those recommendations into contracts will kick-off.
Outreach Survey
The SeamlessAccess Outreach Committee has created a survey to help us better understand how federated identity management is implemented at higher education institutions. The survey is available online and will remain open until 27 March 2020:
https://bostoncollege.co1.qualtrics.com/jfe/form/SV_0Vv0iXWMLZMd9VH
Website Update
A new and improved website for https://SeamlessAccess.org will be published later this month. We hope you will find it significantly easier to navigate! Feedback will be most welcome.
Advanced Integration for Service Providers
There are several levels of integration possible with the SeamlessAccess service:
- Limited - lets you use the SeamlessAccess discovery service for users to find and sign into their preferred Identity Provider, but doesn’t integrate this service into your site
- Standard - lets you use the SeamlessAccess service to display the button on your site, and use the SeamlessAccess discovery and persistence services as integrated components on your site
- Advanced - provides you with the SeamlessAccess persistence service while giving you greater control over the appearance of the service on your site, and what Identity Providers (IdPs) you include in your discovery service
An email went out last month to all Advanced Integration service providers to offer some clarifications about this level of integration, based on what we’ve learned so far through the implementations during the beta phase. You can read that message here: https://seamlessaccess.org/general/2020/01/13/clarifications/.
Following feedback before and during the Internet2 Technology Exchange, the Seamless Access program is reviewing the permissible use of the stored Identity Provider (IdP) preference information when using some of the SeamlessAccess.org integration models (see our “Getting Started” page for more information about the different integration models).
What we realized is that in its current form, authorized Service Providers (SPs) using the advanced integration model may be able to access stored IdP choices before a user logs into that SP’s service. When a website authorized to use SeamlessAccess connects their Federated Identity Management (FIM) service, the website can see the user’s previous choice of IdP before any user authentication occurs. This design choice was originally made to enable full flexibility of the user interface for advanced integrators, for example, to display the preferred IdP in the interface. Further, integrators using the limited and standard integration models are unable to access stored IdP choices.
We now understand that the current situation has some privacy implications that take the service beyond what SeamlessAccess has been promising. For example, a SeamlessAccess-authorized SP could potentially collect information about exactly which IdPs are preferred by the user (which is often correlated to a person’s affiliation) without the user being aware. While the persisted choice of IdP is not considered personally identifiable information (see the WAYF Cloud and P3W Security & Privacy Recommendations from RA21 for more detail) the exposure of any information outside of what matches a more traditional authentication flow runs counter to the principles of SeamlessAccess.
The SeamlessAccess Governance Committee is currently evaluating several options to remediate this unintended possibility, including, but not limited to:
- Changes to the advanced integration API which make it impossible to access the stored IdP choices while still allowing the UI customization and integration with local discovery services for which this model was originally intended.
- A UI mechanism to allow users to grant permission to SPs to access their stored IdP preference information.
- Clear prohibition in the Terms of Use of SeamlessAccess of utilization of stored preference information in any way that is not intended.
In order to become an authorized SP for the advanced integration model using our production service, the SP has to follow a process that includes a review of their proposed integration with SeamlessAccess. The SeamlessAccess governance committee is currently working with appropriate legal counsel to develop a strong Terms of Service and Privacy Statements that will be part of authorizing any new SP. A link to the onboarding process and appropriate policies will be made available on the SeamlessAccess website as soon as they are complete.
As we have more information and documentation on how to integrate with SeamlessAccess, we will let you know.
SeamlessAccess.org is a service designed to help streamline the online access experience for researchers using scholarly collaboration tools, information resources, and shared research infrastructure. This is the monthly update for January 2020, where we catch up on the latest activities within SeamlessAccess.org.
Upcoming Conference Sessions
ALA Midwinter (January 24-28, 2020) Jason Griffey (Director of Strategic Initiatives, NISO) will share the lessons being learned to date from the beta testing of SeamlessAccess, the best practices and policies developed by the existing working groups, and describe what libraries and librarians need to know in order to deliver a simpler, privacy-preserving access experience for users.
NISO Plus (February 23-25, 2020)
Tim Lloyd (CEO, LibLynx) will offer an introduction to SeamlessAccess for those new to the service, and Ralph Youngen (Director, Publishing Systems Integration, American Chemical Society) and Lisa Hinchliffe (Professor, University of Illinois at Urbana-Champaign) will kick off a more in-depth conversation about SeamlessAccess and its implications in the research and library communities.
Community Engagement
The Entity Category and Attribute Bundle working group, a group of librarians, service providers, and federation operators, is working to define appropriate mechanisms around attribute release. Attributes are the information that an identity provider such as a library or research laboratory may share with a service provider, and can include signaling when no attributes at all should be released, when specific attributes should be optional, or when specific attributes are required. The group is currently working through various use cases to determine what makes sense and where the commonalities are when it comes to what attributes are required, and when. After this working group produces its recommendations, a new group that focuses on how to incorporate those recommendations into contracts will kick off.
Terms of Service
The official “Terms of Service” that sets the policies around the use of the SeamlessAccess service is still in progress. We are currently working with legal counsel on that, and the final copy will also be made public once complete.
This guide is for non-technical people who want to understand how attribute release enables secure and privacy-preserving access to online library resources using federated identity management. If you first want to read up on what federated identity management is, you can find a basic introduction here.
What are attributes?
Attributes contain information about an end user that are passed to a publisher or service provider after authentication. Think of a name, email address etc.
An end user working or studying in the Research & Education (R&E) sector often has a user account with their institution. Their institution is the ‘identity provider’ of the user, commonly abbreviated as IdP. During an online authentication workflow, the IdP can often provide additional attributes about the user1 to the organization initiating the process (also known as the Service Provider or SP).
Why are attributes important?
Attributes can be used to transfer information about the end user from the IdP to the service a user wants to access. For example, attributes are commonly used for:
| Use | Example |
|---|---|
| Access control | e.g., only allow users who are full-time staff |
| Cost control | e.g., only allow users with a certain role, or from a certain department |
| Risk control | e.g., avoid the need for (i) users to separately register a username/ password and (ii) 3rd parties to store credentials |
| Convenience | e.g., save search results for subsequent access. And avoid the user having to provide duplicative information to the SP that their IdP already holds |
Attributes and attribute release can be very helpful in ‘doing business’ and enabling users to do their work. To protect user privacy and comply with data protection legislation, it is important to limit the release of personal data.
Types and examples of attributes
These attributes can be classified according to the amount of information they reveal to the SP about the user:
Anonymous identifier:
- Some services want to receive an identifier, for example because they technically need one. The IdP can generate identifiers2 that are unique for every visit and SP
- Real identity unknown (anonymous)
- Does not allow for personalization
Pseudonymous identifier
- IdP-generated identifier3 unique per person/SP-combination
- Real identity unknown by the SP (pseudonymous)
- Personalization possible
Organizational
- Home organization, Entitlements, Role, Department, Location, etc.4
Personal
- Name, email address
How does attribute release work?
In general, the flow goes as follows: a user lands on a web page of a service (an SP), often via a search engine like Google, and clicks a login button that brings them to their IdP, while the SP specifies what attributes it would like to receive. The user signs in at their IdP. After successful authentication, the IdP redirects the user back to the service, while providing zero or more attributes. Graphically:
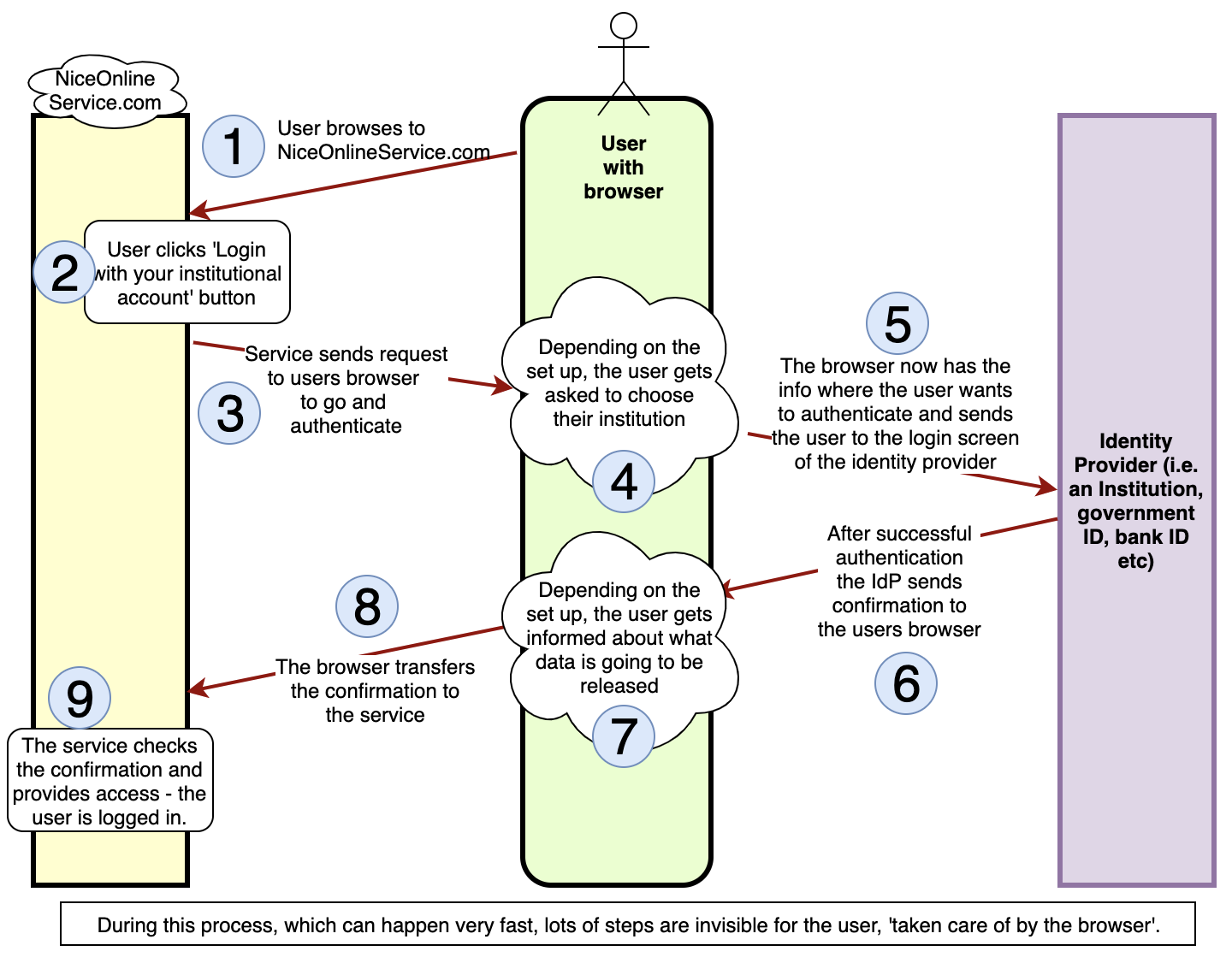
The IdP is always in control of what attributes are released to an individual SP, and has a responsibility to limit attribute release and protect the users privacy. Depending on the national legislation, IdP’s should check to see whether they need a contract between the IdP and SP to release personal information that defines, amongst other things, what other attributes are necessary and how the privacy of the user is protected.
RA21 and recommendations
RA21 has adopted the GÉANT Data Protection Code of Conduct (DPCoCo), an R&E-led initiative that defines behavioural rules for SPs that want to receive user attributes from IdPs. The DPCoCo sets the stage for compliance with the principles behind the EU General Data Protection Regulation (GDPR).
RA21 recommends:
-
For SP’s:
- Only request the least intrusive set of attributes; what you need, not what you want.
- If the service thinks it has good reasons to request more information from the user, the service should provide a profile page in the service, so the user can, on an individual basis, enter more information (like a name, an email address etc).
- Do not retain any extra attributes that you receive.
- Do not use attributes for non-access purposes without prior consent or proper legal basis.
- Delete or anonymize all attributes when no longer needed for service access.
-
For IdP’s:
- Limit attribute exchange during authentication.
- People from IT and libraries to start working together, to discuss attribute release, minimizing attribute release, and informing users about what data is exchanged, why and on what grounds
-
For both:
- Only share anonymous or, if necessary, pseudonymous attributes.
- Make sure there is a proper lawful basis for exchanging attributes.
Here are some example scenarios showing how attribute release can enable different levels of personalization for the user:
| Scenario | Attributes |
|---|---|
| Users access a website or resource that is access controlled by provides full-text articles with no options for personalization | Anonymous attributes |
| Users access a website that provides personalised get content recommendations in its UI based on prior visits/history | Pseudonymous ID |
| Faculty have the ability to purchase ebooks using library funds | Pseudonymous ID, User role |
| Clinicians receive email confirmation of Continuing Education credits received | Pseudonymous ID, User email address (with user consent) |
Related resources
See also: VIDEO: How Federated Authentication Works provides a conceptual understanding of how this technology enables more seamless and privacy-preserving access, including definitions of key terms, such as Service Provider, Identity Provider, and Identity Federation.
FOOTNOTES:
-
Technically, an organization can be (one of many) attribute providers for a user, without also being their identity provider. Typically, an R&E institution acts as both identity provider as well as the main (or only) attribute provider. ↩︎
-
As an example: in SAML the ‘NameID’ attribute can be used to communicate a transient id. The Shibboleth wiki has a nice overview of identifiers. ↩︎
-
As an example: in SAML the ‘Pairwise Subject Identifier’ is the current state of the art identifier (while in older configurations ‘eduPersonTargetedID’ and SAML 2.0 ‘persistent NameID’ is still being used). ↩︎
-
Not all federations release the same set of attributes. But there is a core set which most can supply. ↩︎
Taking the findings of the RA21 initiative to the next level, SeamlessAccess.org intends to support a streamlined federated authentication experience when using scholarly collaboration tools, information resources, and shared research infrastructure. The service will promote digital authentication leveraging an existing single-sign-on infrastructure through one’s home institution, while maintaining an environment that protects personal data and privacy. The service aims to enable simple, trusted use of scholarly resources and services anytime, anywhere, and on any device.
As part of our efforts to encourage organizations that support federated authentication, including publishers and platform providers, we are hosting a hackathon for developers. A hackathon is a hands-on developers meeting that offers individuals an opportunity to sit at a table with the architect or lead developer of a code base and get hands-on support in implementing the open-source software behind SeamlessAccess.org. A hackathon is not a tutorial, nor is it a presentation or conference session, and it is not suitable for non-developers.
Your organization is invited and encouraged to send members of your development team to the event to engage in understanding and developing code (bug fixes, feature enhancements, etc) against either the metadata query system and/or the code behind SeamlessAccess.org (thiss.io). This is a critical time in setting the direction of the service, and understanding how publishers and platform providers expect to integrate with the service is key.
There will be a second T&I Hackathon in the US on 10-11 December 2019, concurrent with the Internet2 Technology Exchange 2019 conference in New Orleans. The SeamlessAccess.org service will be at a different point in its development, and the questions and issues to be discussed are likely to be quite different at the second hackathon.
Participants in the hackathon will need to have the ability to access a test/dev environment for where they can install and test integrations with SeamlessAccess.org. We will provide the Internet connections, the power, and the platform source code.
Registration for the hackathon is part of the overall NORDUnet Technical Workshop. The NORDUnet Technical Workshop (NTW) is is held every two years in Copenhagen. The main event (24-26 September 2019) features a series of workshops on subjects related to research and education networks, including a full day of trust & identity workshops. The NTW brings together 150-200 practitioners from research and education networking communities in the Nordic countries and beyond. The event is held a 5-minute metro ride from Copenhagen airport, 10 minutes from central Copenhagen.